|

GÉNIE MARIN & MÉTÉO | GÉNIE
MÉCANIQUE | GÉNIE ÉLECTRIQUE
GÉNIE ÉNERGÉTIQUE | GÉNIE
CIVIL | GÉNIE BIOLOGIQUE | GÉNIE
AÉROSPATIAL
GÉNIE CHIMIQUE | GÉNIE INDUSTRIEL |
GÉNIE LOGICIEL
| 74.
GÉNIE
INDUSTRIEL (1/2) |
Dernière mise à jour de ce chapitre:
2017-01-31 10:13:27 | {oUUID 1.797}
Version: 3.3 Révision 40 | Avancement:
~60%
vues depuis
le 2012-01-01: 11'103
 LISTE
DES SUJETS TRAITÉS SUR CETTE PAGE LISTE
DES SUJETS TRAITÉS SUR CETTE PAGE
Le Génie Industriel englobe la conception,
l'amélioration
et l'installation
de systèmes. Il utilise les connaissances provenant des sciences mathématiques,
physiques et sociales, ainsi que les principes et méthodes propres à l'art
de l'ingénieur, dans le but de spécifier, prédire et évaluer
les résultats découlant de ces systèmes.
Nous pouvons résumer tous les domaines qui touchent au génie
industriel (et pas seulement... cela peut s'appliquer avec adaptation ad hoc
à l'administration) par l'objectif d'optimiser et contrôler
les performances globales de l'entreprise (coûts, délais, qualité)
car:
On ne peut améliorer que ce que l'on mesure!
Remarquons que certaines techniques de génie industriel ont déjà été abordées
dans d'autres chapitres comme les techniques de gestion quantitatives, l'optimisation
(recherche opérationnelle), l'analyse financière, l'analyse des
files d'attente, etc. et que ce domaine englobe le "génie
qualité".
Dans ce chapitre, nous traiterons uniquement des aspects théoriques minimaux
du SQC (Statistical Quality Control) relatifs au contrôle statistique
de la qualité (dont
c'est le métier du "qualiticien") dans
le cadre de la fabrication et de la mise en production de biens ou de services
et qui constitue le minimum-minimorum de la connaissance de tout ingénieur qualité actif dans une organisation quelconque (industrielle
ou administrative) sous peine d'avoir aucune crédibilité! Par
ailleurs méfiez vous des entreprises - particulièrement des multinationales
- qui recherchent des spécialistes
qualité
maîtrisant Microsoft Excel ou Microsoft Access. Car cela signifiera
qu'elles utilisent des outils non professionnels pour faire un travail qui
lui devrait
pourtant l'être avec
des outils adaptés (et Microsoft Excel ou Microsoft Access
ne le sont pas)!!! Donc
en termes d'organisation interne, vous pouvez vous assurer que
ces entreprises organisent et analysent n'importe quoi, n'importe
comment, avec un outil non adapté et donc que c'est le bordel général
en interne.
Selon l'utilisation, nous distinguons trois domaines principaux qui dans l'ordre
conventionnel sont:
1. Contrôle statistique de processus, surveillance de fabrication ou
réglage de qualité (Statistical
Process Control, SPC). Il s'agit de la surveillance d'un processus de fabrication
pendant la production de produits de masse, pour découvrir des différences
de qualité et pour pouvoir intervenir et conduire directement.
L'ingénieur
doit obligatoirement consulter la norme ISO/TR 13425:2006 Lignes directrices
pour la sélection des méthodes statistiques dans la normalisation
et la spécification ainsi que la norme ISO 8258 Cartes
de contrôle de Shewhart et enfin ISO/TR 18532 Lignes directrices
pour l'application des méthodes statistiques à la qualité et à la
normalisation industrielle avant de
mettre en place des outils SPC au sein de son entreprise. 2. Contrôle de réception ou examen d'échantillon de réception
(Acceptance Sampling, AC). Il s'agit du contrôle d'entrée, d'un
contrôle pendant la production et d'un contrôle final des
produits dans une entreprise (ou usine) sans influence directe sur la production.
Ainsi, le montant
de rebut produit est mesuré. Le contrôle initial sert aussi à refuser
la marchandise arrivante. Elle n'influence par conséquent la production
que de manière indirecte.
L'ingénieur doit obligatoirement consulter la famille de normes
ISO 3591 Règles d'échantillonnage pour les contrôles
par mesures et par attributs avant de mettre en place des outils
de contrôle de réception au sein de son entreprise.
3. Maintenance préventive et contrôle du vieillissement
et de la défaillance et impacts critiques (Analyse des Modes de Défaillances,
de leurs Effets et de leur Criticité, AMDEC). Il s'agit principalement
de calculer la durée de vie de composants ou de machines afin de prévoir
des remplacements à l'avance et les actions y relatives à mener
pour éviter
les situations critiques humaines ou financières.
L'ingénieur doit obligatoirement consulter les normes
CEI 61649 Analyse de Weibull et NF EN 13306 Terminologie
de la maintenance avant
de mettre en place des outils de maintenance préventive au sein
de son entreprise.
Ces trois domaines utilisant les statistiques en général,
l'ingénieur
devra toujours se référer à la famille de normes ISO 3534 Vocabulaire
et symboles, ISO 3534-1 Probabilité et
termes statistiques généraux, ISO 3534-2 Maîtrise
statistique de la qualité, ISO 3534-3 Plans d'expérience.
Indiquons que depuis la fin du 20ème siècle, il est à la
mode de regrouper les deux premiers points dans une méthodologie de
travail appelée "Six Sigma" que nous allons aborder immédiatement.
Enfin, signalons que dans la pratique, pour avoir un intérêt de la direction
d'une entreprise, il faut toujours trouver une relation quantitative entre
non-qualité et les coûts pour pouvoir faire bouger les choses...
SIX SIGMA
Deux objets ne sont jamais rigoureusement identiques. Quelles que soient
les techniques utilisées pour fabriquer ces objets, si précis
soient les outils, il existe une variabilité dans tout processus de
production. L'objectif de tout industriel est que cette variabilité naturelle
demeure dans des bornes acceptables. C'est une préoccupation majeure
dans l'amélioration
de la qualité industrielle.
Un des outils utilisés pour tendre vers cette qualité est la
Maîtrise Statistique des Processus (MSP).Si vous produisez un certain
type d'objets, et si vous souhaitez conserver vos clients pour pérenniser
votre entreprise, vous devez vous assurer que les lots que vous leur livrez
sont conformes à ce qui a été convenu
entre vous, le plus souvent par contrat. Tout industriel sérieux effectue
des contrôles sur les lots produits pour en vérifier la qualité,
qu'il en soit le producteur ou bien qu'il les réceptionne. Diverses
techniques statistiques liées aux prélèvements d'échantillons
sont alors utilisées pour éviter, dans la plupart des cas,
de vérifier un à un tous les objets contenus dans un lot. Ce
contrôle d'échantillons prélevés dans des lots est
indispensable si les contrôles à effectuer détruisent l'objet
fabriqué, comme lors d'une analyse de la dose de composant actif contenue
dans un comprimé. Il existe cependant des cas où l'on préfère
vérifier tous les objets (il est par exemple souhaitable que les freins
d'une voiture fonctionnent et un contrôle du freinage sur un échantillon
dans la production d'un lot d'automobiles ne garantit pas que tous les véhicules
freinent correctement...
Lorsqu'un lot est contrôlé, il est conforme ou il ne l'est pas.
S'il est conforme, on le livre (fournisseur) ou on l'accepte (client). S'il
n'est pas conforme, on peut le détruire, en vérifier un à un
tous les éléments et ne détruire que ceux qui ne sont
pas conformes, etc. Toutes les solutions pour traiter les lots non conformes
sont onéreuses. Si le lot n'est pas conforme, le mal est fait. La MSP
se fixe pour objectif d'éviter de produire des lots non conformes en
surveillant la production et en intervenant dès que des anomalies sont
constatées. Une bonne MSP permet de supprimer un nombre important de
contrôles in fine des lots produits en mettant en place des outils
statistiques de surveillance des processus de fabrication.
Pour résumer, la MSP consiste donc à contrôler le procédé en
cours de fabrication et à agir sur le procédé plutôt
que sur le produit si des problèmes sont détectés. Cette
approche tente donc de remonter la chaîne
de production le plus haut possible pour prévenir l'apparition
de produit défectueux.
Nous parlerons dans ce cas en particulier de contrôle de procédés.
Six Sigma est à l'origine une démarche qualité limitée
dans un premier temps aux techniques de "maîtrise
statistique des procédés" (M.S.P.)
appelée aussi "statistiques des processus
qualité" (S.P.Q. ou S.P.C. en anglais pour Statistical
Process Control). Le lecteur francophone pourra se référer à la
norme AFNOR X06-030 ou différentes normes ISO dont nous ferons référence
plus tard dans le texte.
C'est une méthodologie de travail utile pour satisfaire
les clients dont l'idée est de délivrer des produits/services
de qualité, sachant que la qualité est inversement
proportionnelle à la variabilité. Par ailleurs, l'introduction
de la qualité doit être optimisée afin de ne pas trop
augmenter les coûts.
Le jeu subtil entre ces deux paramètres (qualité/coûts)
et leur optimisation conjointe est souvent associé au terme de "Lean
management". Si nous y intégrons Six Sigma, nous parlons
alors de "Lean
Six Sigma".
Six Sigma intègre tous
les aspects de la maîtrise de la variabilité en entreprise
que ce soit au niveau de la production, des services, de l'organisation
ou de la gestion
(management). D'où son intérêt! Par ailleurs, dans Six
Sigma un défaut doit
être paradoxalement la bienvenue, car c'est une source de progrès
d'un problème
initialement caché. Il faut ensuite se poser plusieurs fois la question "Pourquoi?"
(traditionnellement 5 fois) afin de bien remonter à la source de celui-ci.
Nous distinguons deux types de variabilité dans la pratique:
- La "variabilité inhérente" au
processus (et peu modifiable) qui induit la notion de distribution des mesures
(le plus souvent admise par les entreprises comme étant une loi Normale).
- La "variabilité externe" qui
induit le plus souvent un biais (déviation) dans les distributions
dans le temps.
Les processus de fabrication dans l'industrie de pointe ayant une forte tendance à devenir
terriblement complexes, il faut noter que les composants de base utilisés pour
chaque produit ne sont pas toujours de qualité ou de performance égale. Et
si de surcroît, les procédures de fabrication sont difficiles à établir, la
dérive sera inévitablement au rendez-vous.
Que ce soit pour l'une ou l'autre raison, au final bon nombre de produits
seront en dehors de la normale et s'écarteront ainsi de la fourchette correspondant à la
qualité acceptable pour le client. Cette dérive est fort coûteuse pour l'entreprise,
la gestion des rebuts, des retouches ou des retours clients pour non-conformité générant
des coûts conséquents amputant sérieusement les bénéfices espérés.
Comme nous allons le voir dans ce qui suit, une définition possible assez
juste de Six Sigma est: la résolution de problèmes basée sur l'exploitation
de données. C'est donc une méthode scientifique de gestion.
contrôle qualité
Dans le cadre des études qualité en entreprise, nous renonçons souvent à un
contrôle à 100% à cause du prix que cela engendrerait. Nous procédons alors à une
prise d'échantillons. Ceux-ci doivent bien évidemment être représentatifs,
c'est-à-dire quelconques et d'égales chances (in extenso le mélange est bon).
Le but de la prise d'échantillons étant bien évidemment la probabilité du
taux de défaillance réel du lot complet sur la base des défaillances constatées
sur l'échantillonnage.
Rappelons avant d'aller plus loin que nous avons vu dans le chapitre de Statistiques
la loi hypergéométrique (et son interprétation) donnée
pour rappel par (cf.
chapitre de Statistiques):
 (74.1)
(74.1)
où la notation du coefficient binomial est conforme à celle
définie et choisie
dans le chapitre de Probabilités (donc non-conforme à la norme
ISO 31-11).
Lors d'un échantillonnage, nous avons normalement un paquet de n éléments
dont nous en tirons p. Au lieu de prendre m (nombre entier!)
comme le nombre d'éléments défectueux, nous allons implicitement
le définir
comme étant égal à:
 (74.2)
(74.2)
où  est
la probabilité (supposée connue ou imposée...) qu'une
pièce soit défectueuse.
Ainsi, nous avons pour probabilité de trouver k pièces
défectueuses
dans un échantillon de p pièces parmi n: est
la probabilité (supposée connue ou imposée...) qu'une
pièce soit défectueuse.
Ainsi, nous avons pour probabilité de trouver k pièces
défectueuses
dans un échantillon de p pièces parmi n:
 (74.3)
(74.3)
La probabilité cumulée de trouver k pièces défectueuses (entre 0 et k en
d'autres termes) se calcule alors avec la distribution hypergéométrique cumulative:
 (74.4)
(74.4)
 Exemple: Exemple:
Dans un lot n de 100 machines, nous admettons au maximum que 3 soient
défectueuses (soit que  ).
Nous procédons à un échantillonnage p à chaque sortie de commande de
20 machines. ).
Nous procédons à un échantillonnage p à chaque sortie de commande de
20 machines.
Nous voulons savoir dans un premier temps qu'elle est la probabilité que
dans cet échantillonnage p, trois machines soient défectueuses,
et dans un deuxième temps quel est le nombre de machines défectueuses
maximum autorisé dans
cet échantillonnage p qui nous dirait avec 90% de certitude que
le lot de n machines en contienne que 3 défectueuses.
x |
H(x) |

|
0 |
0.508 |
0.508 |
1 |
0.391 |
0.899 |
2 |
0.094 |
0.993 |
3 |
0.007 |
1.000 |
Tableau: 74.1
- Application de la loi hypergéométrique
Ainsi, la probabilité de tirer en une série de tirages trois machines
défectueuses dans l'échantillon de 20 est de 0.7% et le nombre de pièces défectueuses
maximum autorisé dans cet échantillon de 20 qui nous permet avec au moins 90%
de certitude d'avoir 3 défectueuses est de 1 pièce défectueuse trouvée (probabilité cumulée)!
Les valeurs H(x) peuvent être calculées facilement avec
la version française de Microsoft Excel 11.8346. Par exemple,
la première
valeur est obtenue grâce à la
fonction:
=LOI.HYPERGEOMETRIQUE(0;20;3;100)=0.508
DÉFAUTS/ERREURS
Intéressons-nous donc à exposer pour la culture générale
un exemple pratique et particulier de ce qui n'est qu'une application simple
de la théorie des
statistiques et probabilités. Pour comprendre l'importantance de la
qualité et du concept "zéro défauts", considérons l'exemple général suivant
de l'inventeur de la méthode:
Considérons que le montage d'une voiture de tourisme comprend 2'500
opérations et que chaque opération est parfaite 99 fois sur 100.
A priori, réussir une opération dans 99 % des cas est le signe
d'une maîtrise quasi parfaite de la qualité. Mais en fait, la
perfection de l'ensemble suppose que 2'500 fois de suite, les opérations
soient parfaitement réalisées. Si la production quotidienne se
monte à 2'000 unités, sur les 5 millions d'opérations
effectuées quotidiennement dans notre usine, il y a 1% de défauts
de montage soit 50'000, et en moyenne 25 défauts par voiture, ce qui
est difficilement acceptable. Aussi, admettons que cette usine imaginaire soit
dotée d'un service de contrôle intervenant à la fin du
montage de façon systématique. Cela représente un coût
considérable en heures de travail de contrôle. Si les défauts
peuvent être corrigés, il faudra faire des retouches, remplacer
des pièces peut-être, et travailler dans des conditions imprévues
pour corriger les défauts. S'ils sont trop importants, ces défauts
rendent les produits inutilisables, et les rebuts sont extrêmement coûteux.
Pire encore, si le service de contrôle voit 99% des défauts,
il en subsiste 500 quotidiennement, et cela suppose des retours et réparations
coûteuses ainsi qu'une détérioration
significative de l'image de marque selon les performances de la concurrence.
Cet exemple faisant office de cas d'école, imaginons pour la suite une entreprise
fabricant trois copies d'un même
produit sortant d'une même chaîne, chaque copie étant composée
de huit éléments.
Remarque: Nous
pouvons tout aussi bien imaginer une société de services développant (fabricant)
trois copies d'un logiciel (produit) sortant d'une même équipe de développement
(chaîne), chacun composé d'un nombre égal de modules (éléments).
Supposons que le produit P1 a un défaut, le produit P2 zéro
défauts et le produit P3 deux défauts.
Ici, Six Sigma suppose implicitement que les défauts sont des variables
indépendantes,
ce qui est relativement rare dans les chaînes de fabrication machines mais
plus courant dans les chaînes dans lesquelles des humains sont les intervenants.
Cependant, nous pouvons considérer lors de l'application de la SPC sur
des machines qu'un échantillonnage
du temps dans le processus de mesure équivaut à avoir une variable
aléatoire!!
Remarques:
R1. Dans le cadre de l'exemple du logiciel pris plus haut, l'indépendance
est peu probable si nous ne prenons pas un exemple dans lequel les modules
sont
personnalisés
selon les besoins du client.
R2. L'inconstance des résultats de production de certaines machines
dont les réglages bougent pendant le fonctionnement... (ce qui est courant),
voir que la matière première change de qualité pendant la production (ce qui
est aussi courant!) posent donc de gros problèmes d'application des méthodes
SPC.
La moyenne arithmétique des défauts nommée dans le standard Six Sigma "Defects
Per Unit" (D.P.U.) est alors défini par:
 (74.5)
(74.5)
et donne dans notre exemple:
 (74.6)
(74.6)
ce qui signifie en moyenne que chaque produit a un défaut de conception ou
fabrication. Attention! Cette valeur n'est pas une probabilité pour les simples
raisons qu'elle peut d'abord être supérieure à 1 et qu'ensuite elle a comme
dimension des [défauts]/[produits].
De même, l'analyse peut être faite au niveau du nombre total d'éléments défectueux
possibles qui composent le produit tel que nous sommes amenés naturellement à définir
selon le standard Six Sigma le "Defects per Unit
Opportunity" (D.P.O.):
 (74.7)
(74.7)
ainsi, dans notre exemple, nous avons:
 (74.8)
(74.8)
et ceci peut être vu comme la probabilité d'avoir un défaut par élément de
produit puisque c'est une valeur sans dimensions:
 (74.9)
(74.9)
Par extension, nous pouvons argumenter que 87.5% des éléments
d'une unité n'ont
pas de défauts et comme Six Sigma aime bien travailler avec des exemples
de l'ordre du million (c'est plus impressionnant) nous avons alors les "Defects
Per Million Opportunities" (D.P.M.O.) qui devient:
 (74.10)
(74.10)
ce qui dans notre exemple donne:
 (74.11)
(74.11)
Comme la probabilité D qu'un élément d'une pièce
soit non défectueux
est de 87.5% (soit 12.5% de taux de rebus) alors, par l'axiome des probabilités
conjointes (cf.
chapitre de Probabilités), la probabilité qu'un produit
dans son ensemble soit non défectueux est de:
 (74.12)
(74.12)
ce qui dans notre exemple donne:
 (74.13)
(74.13)
ce qui n'est pas excellent...
Remarque: Dans
Six Sigma, les probabilités conjointes sont aussi naturellement utilisées
pour calculer la probabilité conjointe de produits non défectueux
dans une chaîne
de processus de production P connectés en série. Cette
probabilité conjointe
est appelée dans Six Sigma " Rolled Troughput
Yield" (R.T.Y.) ou " Rendement
Global Combiné" (R.G.C.) et vaut:
 (74.14)
(74.14)

Ce type de calcul étant très utilisé par
les logisticiens qui nomment le résultat "taux
de disponibilité" ainsi que par les chefs de projets pour
la durée d'une phase d'un projet lorsqu'ils considèrent les durées
des tâches
comme indépendantes (sur des structures plus complexes, on parle parfois
"d'arbres de probabilités pondérés").
Ainsi, dans une chaîne industrielle basée sur l'exemple
précédent
pour avoir une quantité Q bien définie de produits
(supposés
utiliser qu'un seul composant de chaque étape) au bout de
la chaîne,
il faudra à l'étape A prévoir:
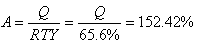 (74.15)
(74.15)
soit 52.42% de composants A de plus que prévu.
Il faudra prévoir à l'étape B:
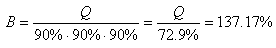 (74.16)
(74.16)
soit 37.17% de composants de plus. Et ainsi de suite...
Rappelons maintenant que la densité de probabilité d'avoir k fois
l'événement p et N-k fois l'événement q dans n'importe
quel arrangement (ou ordre) est donné par (cf. chapitre
de Statistiques):
 (74.17)
(74.17)
et est appelée la loi binomiale ayant pour espérance et écart-type (cf.
chapitre de Statistiques):
 (74.18)
(74.18)
Ainsi, dans le standard Six Sigma, nous pouvons appliquer la loi binomiale
pour connaître quelle est la probabilité d'avoir zéro éléments
défectueux et 8 autres en bon état de marche sur un produit de
la chaîne de fabrication de notre exemple (si tous les éléments
ont la même
probabilité de tomber en panne...):
 (74.19)
(74.19)
et nous retombons bien évidemment sur la valeur obtenue avec les probabilités
conjointes avec:
 (74.20)
(74.20)
Ou la probabilité d'avoir un élément défectueux et sept autres en bon état
sur un produit de la chaîne de fabrication:
 (74.21)
(74.21)
nous voyons que la loi binomiale nous donne 39.26% de probabilité d'avoir
un élément défectueux sur 8 dans un produit.
Par ailleurs, dans le chapitre de Statistiques, nous avons démontré que
lorsque la probabilité p est très faible et tend vers
zéro mais que toutefois
la valeur moyenne  tend
vers une valeur fixe si n tend vers l'infini, la loi binomiale de moyenne tend
vers une valeur fixe si n tend vers l'infini, la loi binomiale de moyenne  avec k épreuves était
alors donnée par une loi de Poisson: avec k épreuves était
alors donnée par une loi de Poisson:
 (74.22)
(74.22)
avec:
 (74.23)
(74.23)
Remarque: Dans
un cadre pratique, il est fait usage de l'estimateur de maximum de vraisemblance
de la loi exponentielle pour déterminer la moyenne et l'écart-type
ci-dessus (cf. chapitre de Statistiques).
Ce que Six Sigma note naturellement:
 (74.24)
(74.24)
avec:
 (74.25)
(74.25)
Ainsi, dans notre exemple, il est intéressant de regarder la valeur
obtenue (qui sera forcément différente étant donné que
nous sommes loin d'avoir une infinité d'individus et que p est
loin d'être
petit) en appliquant une telle loi continue (la loi continue la plus proche
de la
loi binomiale
en fait):
 (74.26)
(74.26)
avec:
 (74.27)
(74.27)
ce qui est un résultat encore plus mauvais qu'avec la loi binomiale pour
nos produits.
Cependant, si p est fixé au départ, la moyenne tend également
vers l'infini théoriquement dans la loi de Poisson de plus l'écart-type  tend également
vers l'infini. tend également
vers l'infini.
Si nous voulons calculer la limite de la distribution binomiale, il s'agira
donc de faire un changement d'origine qui stabilise la moyenne, en 0 par exemple,
et un changement d'unité qui stabilise l'écart, à 1 par exemple.
Ce calcul ayant déjà été fait dans le chapitre de Statistique,
nous savons que le résultat
est la loi Normale:
 (74.28)
(74.28)
Ainsi, dans notre exemple, nous avons  et
l'écart-type est donné par l'estimateur sans biais de l'écart-type (cf.
chapitre de Statistique): et
l'écart-type est donné par l'estimateur sans biais de l'écart-type (cf.
chapitre de Statistique):
 (74.29)
(74.29)
ce qui dans notre exemple donne  . .
Pour déterminer la probabilité nous calculons la valeur numérique
de la loi de Gauss-Laplace (loi Normale) pour  : :
 (74.30)
(74.30)
Ainsi, en appliquant la loi Normale, nous avons 24.19% de chance de tirer
au premier coup un produit défectueux. Cet écart par rapport
aux autres méthodes s'expliquant simplement par les hypothèses
de départ (nombre d'individus
fini, probabilité faible, etc.)
Remarque: Ceux
qui penseraient utiliser la loi triangulaire (cf. chapitres
de Statistiques) doivent tout de suite l'oublier. Effectivement, comme
en qualité la valeur optimiste sera le zéro par définition, la probabilité que
le nombre de défauts soit égal à 0 sera immédiatement de zéro.
INDICES DE CAPABILITÉ
Six Sigma (et aussi la série de normes ISO 22514) définit plusieurs
indices permettant de mesurer pendant le processus de fabrication la capabilité de
contrôle
dans le cas d'un grand nombre de mesures de défauts répartis
souvent selon une loi de Gauss-Laplace (loi Normale).
Basiquement, si nous nous imaginons dans une entreprise, responsable de la
qualité d'usinage d'une nouvelle machine, d'une nouvelle série de pièces, nous
allons être confrontés aux deux situations suivantes:
1. Au début de la production, il peut y avoir de gros écarts
de qualité dus
à des défauts de la machine ou de réglages importants
mal initialisés. Ce sont
des défauts qui vont souvent être rapidement corrigés (sur
le court terme). Dès lors pendant cette période de grosses corrections,
nous faisons des contrôles
par lot (entre chaque grosse correction) et chacun sera considéré comme
une variable aléatoire indépendante et identiquement distribuée
(selon une loi Normale)
mais de moyenne
et écart-type
bien évidemment différent.
2. Une fois les gros défauts corrigés, nous n'allons avoir
en théorie plus
que des défauts minimes très difficilement contrôlables
et ce même sur long
terme.
Alors l'analyse
statistique ne se fait plus forcément par lot de pièces mais
par pièces et
l'ensemble des
pièces sur le long terme est considéré comme un unique
lot à chaque fois.
Ces deux scénarios mettent en évidence que nous n'effectuons
alors logiquement pas les mêmes analyses en début de production
et ensuite sur le long terme. Raison pour laquelle en SPC nous définissons
plusieurs indices (dont les notations sont propre à ce site Internet
car elles changent selon les normes) dont 2 principaux qui sont:
D1. Nous appelons "capabilité potentielle
du procédé
court terme"
ou "indice dispersion court terme" le
rapport entre l'étendue
de contrôle E de
la distribution des valeurs et la qualité de Six Sigma (6 sigma) lorsque
le processus est centré (c'est-à-dire sous contrôle statistique
- les caractéristiques du produit fabriqué varient peu) tel que:
 (74.31)
(74.31)
ce qui s'écrit aussi:
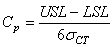 (74.32)
(74.32)
où USL est la limite supérieure de contrôle/tolérance
ou "Upper
Specification Level" (USL) de la distribution et LSL la
limite inférieure ou "Lower Specification
Level" (LSL)
que nous imposons souvent (mais pas toujours!) dans l'industrie comme à distances égales
par rapport à la
moyenne  théorique
souhaitée. La capabilité ci-dessus est donc un indice que nous
chercherons
à maximiser (puisque l'écart-type au dénominateur doit être
minimisé!). théorique
souhaitée. La capabilité ci-dessus est donc un indice que nous
chercherons
à maximiser (puisque l'écart-type au dénominateur doit être
minimisé!).
Ce rapport est utile dans l'industrie dans le sens où l'étendue E (qui
est importante, car elle représente la dispersion/variation du processus)
est assimilée à la "voix du client" (ses exigences)
et le 6 sigma au dénominateur
au comportement réel du procédé/processus censé inclure
quasiment toutes les issues possibles. Il vaut donc mieux espérer que
ce rapport soit au pire égal à l'unité!
Voici typiquement un exemple en gestion de projets où, lorsque le
client ne paie pas pour une modélisation fine du risque fine (le mandataire
accepte alors par contrat une
variation
des délais et coûts qui peut dépasser les 50%), on tombe
sur ce type de distribution :

Figure: 74.1 - Tracé typique d'un plot de contrôle avec étendues et limites
Remarque: En
MSP, l'étendue E est souvent notée IT, signifiant "intervalle
de tolérance".
L'écart-type au dénominateur étant donné par
la relation démontrée dans
le chapitre de Statistiques dans le cas de k variables aléatoires
indépendantes et identiquement distribuées selon une loi Normale
(mais d'écart-type
et moyenne non-identique):
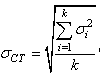 (74.33)
(74.33)
où CT est l'abréviation de "court terme" (abréviation
souvent non précisée dans la pratique car supposée connue
dans le contexte). Cet écart-type
est bien évidemment le meilleur pour le premier scénario dont
nous avons fait mention plus haut. Car entre chaque grosse correction, les
lots sont considérés
comme indépendants et ne peuvent pas être analysés comme
un seul et unique lot (ce serait une aberration!).
Avant de continuer, voyns qu'il nous est possible de construire facilement
un test d'hypothèse pour l'indicateur  .
Effectivement, en se rappelant que nous avons démontré dans le chapitre
de Statistique que: .
Effectivement, en se rappelant que nous avons démontré dans le chapitre
de Statistique que:
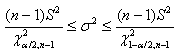 (7.34)
(7.34)
Il est alors immédiat que:
(7.35)
et in extenso:
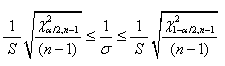 (7.36)
(7.36)
Et dès lors:
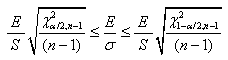 (7.37)
(7.37)
Et en adaptant l'écriture au domaine du génie industriel,
il vient:
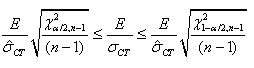 (7.38)
(7.38)
ou encore:
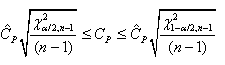 (7.39)
(7.39)
et nous pouvons appliquer le même raisonnement pour tous
les types d'indicateurs du même genre que nous verrons par la site!
Remarque: Dans le cadre de notre étude
plus loin des cartes de contrôle, nous verrons qu'il est possible d'utiliser
des expressions particulières pour l'écart-type lorsque nous
travaillons avec des échantillons
de mesures. Ces expressions seront basées pour l'une sur la loi du Khi-deux
et pour l'autre les statistiques d'ordre.
Attention cependant! Comme souvent dans la situation court terme (lors de
la correction des grosses sources d'erreurs donc) les lots de tests sont petits,
même très petits, afin de diminuer les coûts en production.
Dès lors l'écart-type
se trouvant sous la racine (qui est l'estimateur de maximum de vraisemblance
de la loi Normale) n'a pas une valeur vraiment correcte... Il est alors bon
d'utiliser soit d'autres méthodes de calcul assez empiriques comme le
font de nombreux
logiciels, soit de calculer un intervalle de confiance de l'indice de capabilité
en calculant l'intervalle de confiance de l'écart-type court terme comme
nous l'avons vu dans le chapitre de Statistiques.
D2. Nous appelons "Performance globale du procédé long
terme" le
rapport entre l'étendue de contrôle E de la distribution des valeurs
et la qualité de Six Sigma (6 sigma) lorsque le
processus est centré tel que:
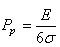 (74.40)
(74.40)
ce qui s'écrit aussi:
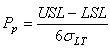 (74.41)
(74.41)
L'écart-type au dénominateur étant donné cette
fois par le cas où nous considérons tous les gros défauts
corrigés et le processus
stable afin de considérer toutes les pièces fabriquées comme
un seul et unique lot de contrôle:
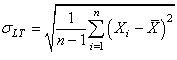 (74.42)
(74.42)
où LT est l'abréviation de "long terme" (abréviation
souvent non précisée dans la pratique car supposée connue
dans le contexte).
Cet écart-type est bien évidemment le meilleur pour le deuxième
scénario dont nous avons fait mention plus haut. Car les variations
étant maintenant, par hypothèse, toutes petites, l'ensemble
de la fabrication peut être supposé comme étant un seul
et unique lot de contrôle sur le long
terme (bon cela n'empêche pas qu'il faut parfois nettoyer les valeurs
extrêmes
qui peuvent se produire).
Le tolérancement des caractéristiques est donc très important pour l'obtention
de la qualité et de la fiabilité des produits assemblés. Traditionnellement,
une tolérance s'exprime sous la forme d'un bipoint [Min,Max]. Une caractéristique
est alors déclarée conforme si elle se situe dans les tolérances.
Le problème
du tolérancement consiste à tenter de concilier la fixation des limites
de variabilité acceptable les plus larges possibles pour
diminuer les coûts de production et d'assurer un niveau de qualité optimal
sur le produit fini.
Deux approches tentent de résoudre ce problème:
1. Le tolérancement au pire des cas garantit l'assemblage dans toutes
les situations à partir
du moment où les caractéristiques élémentaires sont dans
les tolérances.
2. Le tolérancement statistique tient compte de la faible probabilité d'assemblages
d'extrêmes entre eux et permet d'élargir de façon importante les tolérances
pour diminuer les coûts et c'est donc à celui-ci que nous allons nous
intéresser
ici comme vous l'aurez compris.
Un processus est dit "limite capable" (soit
limite stable par rapport aux exigences du client en d'autres termes) s'il
le ratio donné ci-dessus (en choisissant 6 fois l'écart-type)
est supérieur à 1. Mais dans l'industrie, on préfère
prendre en réalité la valeur de ~1.33 dans le cas d'une distribution
Normale des données.
Bien évidemment, la valeur  de
l'écart-type peut être calculée en utilisant les estimateurs
de maximum de vraisemblance avec ou sans biais vus dans le chapitre de Statistiques
mais
il ne s'agit en aucun cas dans la réalité pratique de l'écart-type
théorique mais uniquement d'un estimateur! Par ailleurs, nous verrons
plus loin qu'en fonction de l'écart-type utilisé, les notations
changent! de
l'écart-type peut être calculée en utilisant les estimateurs
de maximum de vraisemblance avec ou sans biais vus dans le chapitre de Statistiques
mais
il ne s'agit en aucun cas dans la réalité pratique de l'écart-type
théorique mais uniquement d'un estimateur! Par ailleurs, nous verrons
plus loin qu'en fonction de l'écart-type utilisé, les notations
changent!
Remarque: En
entreprise, il faut faire attention car l'instrument de mesure rajoute son
propre écart-type (erreur) sur celui de la production.
Comme nous l'avons démontré au chapitre de Statistiques, l'erreur-type
(écart-type
de la moyenne) est:
 (74.43)
(74.43)
Dans la méthodologie Six Sigma, nous prenons alors souvent pour les
processus
à long terme et sous contrôle:
 (74.44)
(74.44)
quand nous analysons des cartes de contrôle dont les variables aléatoires
sont des échantillons de n variables aléatoires indépendantes
et identiquement distribuées et que les limites n'ont pas été imposées
par un client ou par une politique interne ou des contraintes techniques! Bien évidemment,
il faut bien être
conscient que UCL et LCL n'ont pas la même expression
dans des cas plus complexes et donc pour des distributions autres que la loi
Normale!
Par ailleurs, l'expression précédente diffère aussi
pour les processus à court
terme, car l'exemple donné ci-dessus est pour un cas de mesures sur
le long terme uniquement pour rappel!
Comme le montrent les deux exemples ci-dessous:

Figure: 74.2 - Deux plots de mesures sous contrôle statistique avec une capabilité
différente
L'indice impose
que la moyenne (l'objectif) est centrée entre LSL et USL. Dès lors, la moyenne
est confondue avec ce que nous appelons la "cible" T du
processus.
Mais la moyenne dans
la réalité peut être décalée par rapport à l'objectif T initial qui
doit lui toujours (dans l'usage courant) être à distance égale entre USL et
LSL comme le montre la figure ci-dessous dans le cas particulier d'une
loi Normale:

Figure: 74.3 - Mesures sous contrôle statistique décalé par rapport à la cible
Mais ce n'est pas forcément le cas dans la réalité où les ingénieurs (quelque
soit leur domaine d'application) peuvent choisir des LSL et USL asymétriques
par rapport à la moyenne ne serait-ce que parce que la loi n'est pas toujours
Normale
(typiquement
le
cas en gestion de projets...)! D'où la définition suivante:
D2. Nous appelons alors "Capabilité
potentielle décentrée court terme du procédé" (dans
le cas décentré) ou "Process
Capability Index (within)" la relation:
 (74.45)
(74.45)
avec:
 (74.46)
(74.46)
où  est
appelé le "dégré de biais" ou
"indice de position" et T le "target" donné naturellement
par: est
appelé le "dégré de biais" ou
"indice de position" et T le "target" donné naturellement
par:
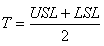 (74.47)
(74.47)
qui donne le milieu de la distribution relativement au bi-point [LSL,USL]
imposé (ne pas oublier que l'écart-type au dénominateur
de la relation antéprécédente est l'écart-type
court terme!).
Au fait cet indicateur de capabilité de contrôle peut sembler
très artificiel, mais il ne l'est pas totalement... Effectivement, il
y a quelques valeurs remarquables (celles qui intéressent l'ingénieur)
qui permettent de se faire une bonne idée de ce qu'il se passe avec
celui-ci:
1. Si la moyenne et la cible sont confondues, nous avons alors:
 (74.48)
(74.48)
nous nous retrouvons donc avec  et
donc et
donc  et
le critère de jugement de la valeur de l'indice sera basé sur
l'indice de capabilité centré court terme. et
le critère de jugement de la valeur de l'indice sera basé sur
l'indice de capabilité centré court terme.
2. Si faute d'un mauvais contrôle du processus nous avons:
 (74.49)
(74.49)
alors la moyenne est
soit au-dessus de USL soit en dessous de LSL ce qui a pour
conséquence d'avoir  et
donc et
donc  . .
3. Si nous avons:
 (74.50)
(74.50)
alors la moyenne est
comprise entre les valeurs USL et LSL ce qui a pour conséquence d'avoir  et
donc et
donc  . .
4. Si nous avons:
 (74.51)
(74.51)
alors cela signifie simplement que la moyenne est confondue avec USL ou LSL et nous avons alors  et et  . .
Comme l'interprétation reste cependant délicate et difficile,
nous construisons les indices de capabilité unilatéraux "Upper
Capability Index CPU" et "Lower Capability
Index CPL" donnés par:
 (74.52)
(74.52)
que nous chercherons bien évidemment aussi à maximiser. Voyons d'où viennent
ces deux valeurs et comment les utiliser:
Démonstration:
D'abord, nous avons besoin de deux formulations particulières du degré de
biais k.
Si:
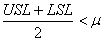 (74.53)
(74.53)
alors nous pouvons nous débarrasser de la valeur absolue:
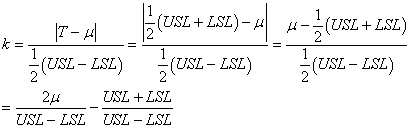 (74.54)
(74.54)
Si:
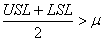 (74.55)
(74.55)
alors nous pouvons nous débarrasser de la valeur absolue:
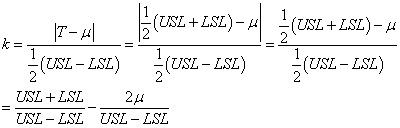 (74.56)
(74.56)
Nous avons alors lorsque 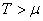 : :
 (74.57)
(74.57)
et respectivement lorsque 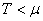 : :
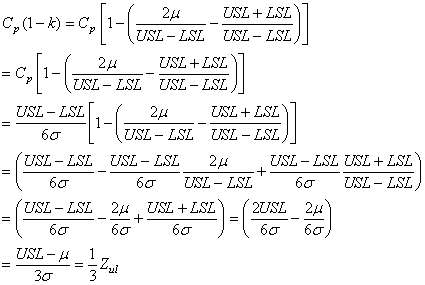 (74.58)
(74.58)
 C.Q.F.D. C.Q.F.D.
À long terme, dans certaines entreprises, il est intéressant
de savoir qu'elles sont les plus mauvaises valeurs prises par les indices CPU et CPL
(c'est le cas dans le domaine de la production mais pas forcément
de la gestion de projets)
Les plus mauvaises valeurs étant trivialement les plus petites, nous
prenons souvent (avec quelques unes des notations différentes que l'on
peut trouver dans la littérature spécialisée...):
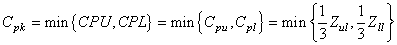 (74.59)
(74.59)
Voici par exemple un diagramme d'analyse de la capabilité généré
par le logiciel Minitab 15.1.1 (en anglais) avec les différents
facteurs susmentionnés
sur un échantillon de 68 données suivant une loi Normale (un
test de normalité a été fait avant):

Figure: 74.4 - Diagramme de capabilité généré avec Minitab 15.1.1
Deux lectures typiques sont possibles (nous expliquerons la partie inférieure
gauche du graphique plus loin):
1. En production: Le processus est capable (valeur >1.33) mais avec
une (trop) forte déviation vers le gauche par rapport à la cible
définie,
ce qui n'est pas bon (CPL ayant
la
valeur la plus petite) et doit être corrigé.
2. En gestion de projets: Les tâches redondantes sont sous contrôle
(valeur
>1.33) mais avec une forte déviation vers le gauche, ce qui peut être
bon si notre objectif est de prendre de l'avance par rapport au planifié (rien à corriger).
Il faut vraiment prendre garde au fait que dans la réalité, il
n'est pas toujours possible de prendre la loi Normale, or tous les exemples
donnés ci-dessus sont basés sur cette hypothèse simplificatrice.
Toujours le cadre de la gestion de la qualité en production, la figure
ci-dessous représente bien la réalité dans le cadre d'un processus court ou
long terme:

Figure: 74.5 - Processus court/long terme (source: MSP/SPC de Maurice Pillet)
Chaque petite gaussienne en gris clair, représente une analyse de
lots assimilé au concept de "dispersion instantanée".
Nous voyons bien que leurs moyennes ne cessent de bouger pendant la période
de mesures (que cette variation soit grande ou très faible) et c'est
ce que nous appelons la "dispersion globale".
Le but dans les organisations (industries ou administrations) est de faire
en sorte que la variabilité instantanée ou globale soit limitée au maximum.
Or la relation définissant  supposait,
comme nous l'avons mentionné, que le processus est sous contrôle centré (donc
toutes les gaussiennes sont alignées) et sur une optique court terme. supposait,
comme nous l'avons mentionné, que le processus est sous contrôle centré (donc
toutes les gaussiennes sont alignées) et sur une optique court terme.
De même, la relation définissant 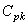 supposait,
comme nous l'avons mentionné, que le processus est sous contrôle, sur
une optique court terme et décentré par choix (ou à cause du
fait que la loi n'est pas Normale). supposait,
comme nous l'avons mentionné, que le processus est sous contrôle, sur
une optique court terme et décentré par choix (ou à cause du
fait que la loi n'est pas Normale).
Par contre, si le processus n'est pas centré parce qu'il n'est pas
sous contrôle
alors qu'il devrait l'être, la variable aléatoire mesurée
est la somme de la variation aléatoire des réglages X de
la machine et des variations aléatoires
non contrôlables des contraintes des pièces Y.
L'écart-type total est alors, si les deux variables aléatoires
suivent une loi Normale (et surtout qu'elles sont indépendantes....), la
racine carrée
de la somme des écarts-types
(cf.
chapitre de Statistiques):
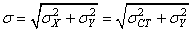 (74.60)
(74.60)
Or, si nous n'avons qu'une seule mesure, il vient en prenant l'estimateur
biaisé (c'est un peu n'importe quoi de l'utiliser dans ce cas-là mais
bon...):
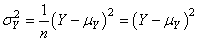 (74.61)
(74.61)
Or dans le cas d'étude qui nous intéresse Y représente la moyenne
expérimentale (mesurée) du processus qu'on cherche à mettre sous contrôle.
Cette moyenne est notée traditionnellement m dans le domaine.
Ensuite, 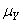 n'étant
pas connu on prend ce qu'il devrait être: c'est la cible T du processus.
Ainsi, nous introduisons un nouvel indice appelé "Capabilité potentielle
décentrée
moyenne court terme du procédé": n'étant
pas connu on prend ce qu'il devrait être: c'est la cible T du processus.
Ainsi, nous introduisons un nouvel indice appelé "Capabilité potentielle
décentrée
moyenne court terme du procédé":
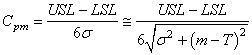 (74.62)
(74.62)
où encore une fois il faut se rappeler que l'écart-type dans la racine au
dénominateur est l'écart-type court terme!
Nous voyons immédiatement que plus 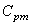 est
proche de mieux
c'est (dans les domaines de production du moins). est
proche de mieux
c'est (dans les domaines de production du moins).
Nous avons donc finalement les trois indices de capabilités court terme centré et
non centré les plus courants (nous avons délibérément choisi d'uniformiser
les notations et de mettre le maximum d'infos dans celles-ci):
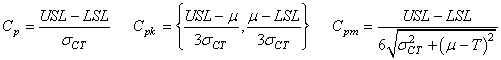 (74.63)
(74.63)
De même nous avons aussi les trois indices de capabilités long terme centré et
non centré les plus courants (nous avons délibérément choisi d'uniformiser
les notations et de mettre le maximum d'infos dans celles-ci):
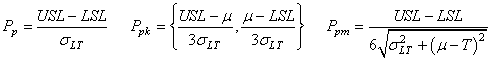 (74.64)
(74.64)
Enfin, indiquons que bien que ce soit pas très pertinent, il arrive parfois
que certains ingénieurs fassent les deux analyses (court terme + long terme)
en même temps sur la même base de données de mesures.
Remarque: Indiquons que les capabilités
procédés d'un procédé
industriel lorsque appliquées à des machines sont notées
respectivement  .
Bref... pour faire le tri se référer aux normes ISO 22514-2:2013
ou l'ancienne version ISO 21747:2006.
Cependant, pour faire de l'analyse objective sur les indices de capabilité vus
jusqu'à maintenant, il faudrait d'abord que les instruments de mesure soient
eux-mêmes capables... ce que nous appelons souvent les "méthodes R&R"
(Répétabilité,
Reproductibilité).
Le principe de base (car le principe avancé consiste à faire une ANOVA à
deux facteurs avec répétition) consiste alors à évaluer
la dispersion courte terme ou respectivement long terme de l'instrument de
mesure
afin de
calculer
une "capabilité de
processus de contrôle" définie par:
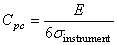 (74.65)
(74.65)
ou encore selon l'industrie certain utilisent l'écart-type basé sur l'étendue
et que nous avons démontré dans le chapitre de Statistiques lors de notre
étude des valeurs extrêmes et appelée "Variation
d'Équipement" consistant donc à calculer la moyenne
des étendues de toutes les mesures faites par différents opéraeurs et de
la diviser par la constante de Hartley:
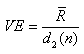 (74.66)
(74.66)
Dans les cas classiques, nous déclarons le moyen de contrôle capable
pour un suivi MSP lorsque cette capabilité est supérieure à 4
et nous allons de suite voir pourquoi. Rappelons pour cela d'abord que:
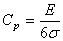 (74.67)
(74.67)
Mais la variance observée est au fait la somme de la "vraie" variance
et de celle de l'instrument telle que:
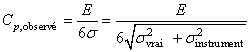 (74.68)
(74.68)
Or nous avons:
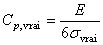 et et 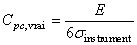 (74.69)
(74.69)
En mettant le tout au carré, nous en déduisons:
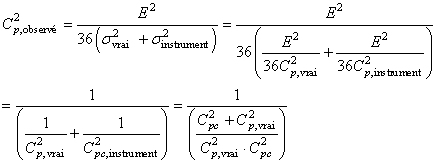 (74.70)
(74.70)
D'où:
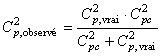 (74.71)
(74.71)
Ce qui nous donne:
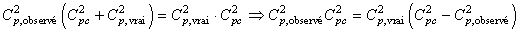 (74.72)
(74.72)
Soit:
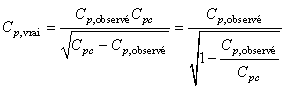 (74.73)
(74.73)
Ce qui se traduit par le graphique de la figure suivante qui montre bien
l'intérêt d'un 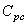 au
moins égal à 4! au
moins égal à 4!

Figure: 74.6 - Relation entre capabilité vraie et mesurées
Dans la pratique, signalons que pour déterminer on
se sert d'une pièce étalon mesurée par interférométrie LASER et s'assurer ensuite
que tous les essais répétés de mesure se fassent sur les deux mêmes points
de mesure.
Une fois ceci fait, on effectue plusieurs mesures de la cote étalon et on
prend l'écart-type de ces mesures. Ce qui donnera le 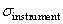 . .
L'étendue E est elle imposée par le client ou par des ingénieurs internes à l'entreprise.
Elle sera souvent prise comme étant au plus dixième de l'unité de tolérance
d'une pièce.
Par exemple, si nous avons un diamètre intérieur de 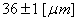 (étendue
de tolérance de 2 microns ce qui est déjà du haut de gamme niveau
précision,
car à notre époque le standard se situe plutôt autour des 3!), notre
appareil devra alors avoir selon la règle précédemment
citée une étendue de 0.2 microns...
Il est alors aisé de déterminer qu'elle devra être l'écart-type
maximum de l'instrument si on se fixe une capabilité de processus de
contrôle de 4 (et
encore... 4 c'est grossier!). (étendue
de tolérance de 2 microns ce qui est déjà du haut de gamme niveau
précision,
car à notre époque le standard se situe plutôt autour des 3!), notre
appareil devra alors avoir selon la règle précédemment
citée une étendue de 0.2 microns...
Il est alors aisé de déterminer qu'elle devra être l'écart-type
maximum de l'instrument si on se fixe une capabilité de processus de
contrôle de 4 (et
encore... 4 c'est grossier!).
Certains ingénieurs apprécient de savoir à combien d'éléments en millions
d'unités produites (parties par million: PPM) seront considérées comme défectueuses
relativement.
Le calcul est alors aisé puisque l'ingénieur a à sa disposition au moins
les informations suivantes:
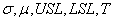 (74.74)
(74.74)
et que les données suivent une loi Normale alors il est immédiat que (cf.
chapitre de Statistiques):
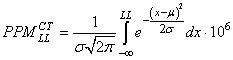 (74.75)
(74.75)
et:
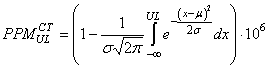 (74.76)
(74.76)
valeurs très aisées à obtenir avec n'importe quel tableur
comme Microsoft Excel par exemple.
Nous avons alors
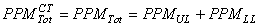 (74.77)
(74.77)
il en est de même pour la capabilité long terme (il suffit de prendre
alors l'expression correspondante de l'écart-type).
NIVEAUX DE QUALITÉS
Signalons un point important relativement à Six Sigma. Au fait, objectivement,
l'idée de cette méthode est, certes, de faire de la SPC (entre
autres, mais ça
ce n'est pas nouveau) mais surtout de garantir au client selon la tradition
couramment admise avec un écart-type ayant une borne supérieure
de 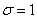 avec
une déviation à la moyenne (en valeur absolue) de 1.5 avec
une déviation à la moyenne (en valeur absolue) de 1.5 par
rapport à la cible, ce qui garantit au plus 3.4 PPM (c'est-à-dire 3.4
rejets par million). par
rapport à la cible, ce qui garantit au plus 3.4 PPM (c'est-à-dire 3.4
rejets par million).
Remarque: Ce choix empirique vient de la mise
en pratique de la méthode Six Sigma par son créateur (Bill Smith).
Il a observé dans
son entreprise (Motorola) que sous contrôle statistique, il avait
quasiment systématiquement une déviation comprise entre 1.2
et 1.8 à
la moyenne pour tous ses procédés industriels.
Voyons d'où vient cette dernière valeur à l'aide des deux tableaux suivants:
1. D'abord construisons un tableau de type idéal qui présente des données
d'un procédé court terme (mais les calculs sont parfaitement identiques pour
du long terme) centré sur la cible (de cible nulle ici, ce qui est un cas typique),
de moyenne nulle (donc sur la cible et alors donc 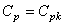 )
et d'écart-type unitaire avec USL et LSL symétriques (ce qui restreint par
contre le champ d'application): )
et d'écart-type unitaire avec USL et LSL symétriques (ce qui restreint par
contre le champ d'application):
Cp |
Cpk |
Défauts (PPM) |
Niveau de qualité Sigma |
Critère |
0.5 |
0.5 |
133614 |
1.5 |
Mauvais |
0.6 |
0.6 |
71861 |
1.8 |
|
0.7 |
0.7 |
35729 |
2.1 |
|
0.8 |
0.8 |
16395 |
2.4 |
|
0.9 |
0.9 |
6934 |
2.7 |
|
1 |
1 |
2700 |
3 |
|
1.1 |
1.1 |
967 |
3.3 |
|
1.2 |
1.2 |
318 |
3.6 |
|
1.3 |
1.3 |
96 |
3.9 |
Limite |
1.4 |
1.4 |
27 |
4.2 |
|
1.5 |
1.5 |
6.8 |
4.5 |
|
1.6 |
1.6 |
1.6 |
4.8 |
|
1.7 |
1.7 |
0.34 |
5.1 |
|
1.8 |
1.8 |
0.067 |
5.4 |
|
1.9 |
1.9 |
0.012 |
5.7 |
|
2 |
2 |
0.002 |
6 |
Excellent |
Tableau: 74.2
- Capabilité, Niveau de qualité Sigma et P.P.M. dans procédé centré
où toutes les données sont obtenues à l'aide des relations suivantes à partir
de l'indice de capabilité potentielle uniquement:
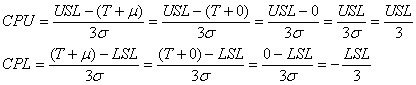 (74.78)
(74.78)
si l'écart-type est réduit (ce qui peut toujours être fait
et ne change point la justesse des résultats!). Et puisque dans le tableau
ci-dessus LSL et USL sont
symétriques par rapport à la cible:
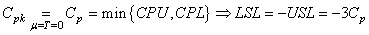 (74.79)
(74.79)
et les PPM sont conformément à ce que nous avons vu juste avant donnés
par:
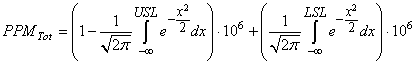 (74.80)
(74.80)
et donc puisque dans l'exemple ci-dessus LSL et USL sont symétrique par rapport à la
cible cela se simplifie en:
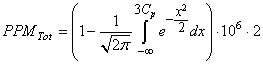 (74.81)
(74.81)
où, par exemple, la valeur du PPM donnée à la ligne "Limite" est obtenue
avec Maple 4.00b à l'aide de la commande:
>evalf((1-1/sqrt(2*Pi)*int(exp(-x^2/2),x=-infinity..3.9))*2)*1E6;
ou avec la version anglaise de Microsoft Excel 11.8346:
=(1-NORMDIST(3.9;0;1;1))*1E6
Rappelons que le "niveau
de qualité sigma" noté 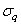 est
au fait donné à l'aide du tableau suivant que nous avions construit
dans le chapitre de Statistiques: est
au fait donné à l'aide du tableau suivant que nous avions construit
dans le chapitre de Statistiques:
Niveau
de qualité Sigma |
Taux
de non-défection assuré en % |
Taux
de défection en parties par million |

|
68.26894 |
317'311 |

|
95.4499 |
45'500 |

|
99.73002 |
2'700 |

|
99.99366 |
63.4 |

|
99.999943 |
0.57 |

|
99.9999998 |
0.002 |
Tableau: 74.3
- Capabilité, Taux de non-défection en % et PPM
et pour lequel nous avions donné la commande Maple 4.00b pour obtenir les
valeurs qui sont valables pour tout écart-type et toute espérance!
2. Maintenant construisons le tableau au pire selon Six Sigma, soit un tableau
en procédé non centré (c'est-à-dire où n'est
pas satisfait) avec une déviation
de la moyenne de 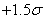 (donc à droite
mais on pourrait prendre à gauche et les résultats seraient les mêmes)
par rapport à la
cible et d'écart-type unitaire avec USL et LSL symétriques (ce
qui restreint toujours le champ d'application): (donc à droite
mais on pourrait prendre à gauche et les résultats seraient les mêmes)
par rapport à la
cible et d'écart-type unitaire avec USL et LSL symétriques (ce
qui restreint toujours le champ d'application):
Cp |
Cpk |
Défauts (PPM) |
Niveau de qualité Sigma |
Critère |
0.5 |
0 |
501350 |
1.5 |
Mauvais |
0.6 |
0.1 |
382572 |
1.8 |
|
0.7 |
0.2 |
27412 |
2.1 |
|
0.8 |
0.3 |
184108 |
2.4 |
|
0.9 |
0.4 |
115083 |
2.7 |
|
1 |
0.5 |
66810 |
3 |
|
1.1 |
0.6 |
35931 |
3.3 |
|
1.2 |
0.7 |
17865 |
3.6 |
|
1.3 |
0.8 |
8198 |
3.9 |
Limite |
1.4 |
0.9 |
3467 |
4.2 |
|
1.5 |
1 |
1350 |
4.5 |
|
1.6 |
1.1 |
483 |
4.8 |
|
1.7 |
1.2 |
159 |
5.1 |
|
1.8 |
1.3 |
48 |
5.4 |
|
1.9 |
1.4 |
13 |
5.7 |
|
2 |
1.5 |
3.4 |
6 |
Excellent |
Tableau: 74.4
- Capabilité, Niveau de qualité Sigma et P.P.M. dans procédé décentré
où toutes les données sont obtenues à l'aide des relations suivantes à partir
de l'indice de capabilité potentielle uniquement:
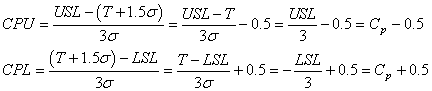 (74.82)
(74.82)
et donc:
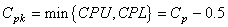 (74.83)
(74.83)
d'où:
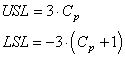 (74.84)
(74.84)
et les PPM sont conformément à ce que nous avons vu juste avant donnés
par:
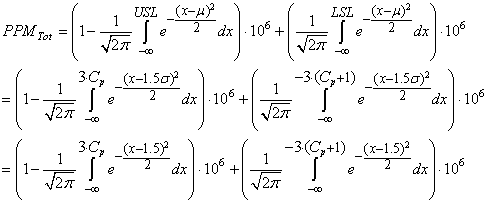 (74.85)
(74.85)
où la ligne "Limite" du tableau précédent est par exemple obtenue
avec Maple 4.00b à l'aide
de la commande:
>evalf((1-1/sqrt(2*Pi)*int(exp(-(x-1.5)^2/2),x=-infinity..(1.3*3))))*1E6+evalf((1/sqrt(2*Pi)*int(exp(-(x-1.5)^2/2),x=-infinity..-(3*(1.3+1)))))*1E6;
ou avec la version anglaise de Microsoft Excel 11.8346:
=(((1-NORMDIST(3*1.3;1.5;1;1))+NORMDIST(-3*(1.3+1);1.5;1;1)))*1E6
On comprend enfin en voyant cette fameuse ligne "Limite", pourquoi
un procédé sous-contrôle est dit "limite capable" avec
un indice de capabilité potentielle de 1.33 étant donné le
nombre de PPM!
Donc, le but dans la pratique c'est bien évidemment d'être dans la
situation du premier tableau avec pour valeur correspondante dans ce premier
tableau à un
niveau de qualité sigma de 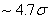 pour
avoir l'équivalent des 3.4 PPM du deuxième tableau (car il est
plus facile de centrer un procédé que de contrôler ses écarts). pour
avoir l'équivalent des 3.4 PPM du deuxième tableau (car il est
plus facile de centrer un procédé que de contrôler ses écarts).
Toute l'importance des valeurs calculées ci-dessous est dans l'application
de procédés de fabrication à n-étapes
en série
(considérés sous la dénomination de "processus"). Cette
application sera présentée dans le chapitre sur les Techniques de Gestion.
Exemple:
Faisons un résumé de tout cela en considérant une nouvelle
petite production de 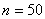 pièces
par lot de 10 (afin d'ajuster en cours de production). La mesure de côtes de
5 pièces chaque heure pendant 10 heures avec une tolérance de pièces
par lot de 10 (afin d'ajuster en cours de production). La mesure de côtes de
5 pièces chaque heure pendant 10 heures avec une tolérance de 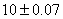 soit
en termes de centièmes une étendue de: soit
en termes de centièmes une étendue de:
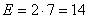 (74.86)
(74.86)
et une cible de 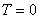 (en
termes d'écarts). Nous avons les données suivantes: (en
termes d'écarts). Nous avons les données suivantes:
| |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
1 |
-2 |
-4 |
-1 |
0 |
4 |
0 |
3 |
0 |
1 |
-1 |
2 |
0 |
-3 |
0 |
-2 |
1 |
-2 |
0 |
1 |
-1 |
2 |
3 |
-1 |
0 |
-3 |
-1 |
0 |
0 |
-1 |
-1 |
3 |
1 |
4 |
1 |
1 |
-2 |
2 |
2 |
0 |
1 |
0 |
4 |
0 |
5 |
-1 |
-1 |
-3 |
0 |
0 |
3 |
3 |
2 |
1 |
0 |

|
-0.6 |
-1.4 |
-1.8 |
-0.2 |
1.4 |
0.2 |
1.2 |
0.4 |
1.6 |
0.5 |

|
1.14 |
2.07 |
1.30 |
1.48 |
1.67 |
1.79 |
1.79 |
1.14 |
1.95 |
1.14 |
Tableau: 74.5
- Application d'analyse de maîtrise statistique des procédés
Nous voyons immédiatement que le processus de fabrication a été non
stationnaire pendant cette première production, il faudra donc apporter
des corrections à l'avenir:

Figure: 74.7 - Preuve par un tracé que le processus est non stationnaire
ou sous forme de carte de contrôle (comme je les aime) avec la représentation
d'un écart-type de 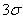 (ce
qui est suffisant pour des petites quantités des pièces bon marché à fabriquer): (ce
qui est suffisant pour des petites quantités des pièces bon marché à fabriquer):

Figure: 74.8 - Petite carte de contrôle empirique
Donc, on devine quand même que le processus est limite...
Remarque: Une chose intéressante c'est
que l'on peut analyser aussi ce graphique en utilisant les outils mathématiques
de l'analyse des séries temporelles
(cf. chapitre d'Économie).
D'abord, si nous voulons faire une étude statistique pertinente des différentes
données ci-dessus nous pouvons calculer la moyenne générale des écarts qui
sous l'hypothèse d'une distribution Normale est la moyenne arithmétique (cf.
chapitre de Statistiques):
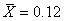 (74.87)
(74.87)
Ensuite l'écart-type des données de toutes les pièces est de:
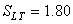 (74.88)
(74.88)
en utilisant l'estimateur de maximum de vraisemblance de la variance de la
loi Normale:
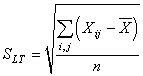 (74.89)
(74.89)
Donc, l'erreur-standard (l'estimateur de l'écart-type de la moyenne)
est de:
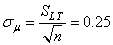 (74.90)
(74.90)
Donc, l'intervalle de confiance à 95% de la moyenne est de (cf.
chapitre de Statistiques):
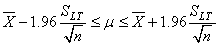 (74.91)
(74.91)
Soit dans notre cas:
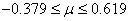 (74.92)
(74.92)
Et l'inférence statistique avec notre écart-type long terme utilisant le
test d'hypothèse bilatéral du 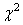 donne
(cf. chapitre de Statistiques): donne
(cf. chapitre de Statistiques):
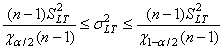 (74.93)
(74.93)
Ce qui nous donne dans notre cas:
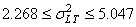 (74.94)
(74.94)
soit:
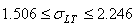 (74.95)
(74.95)
Nous remarquons alors que sur une analyse long terme, nous avons les intervalles:
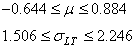 (74.96)
(74.96)
Calculons maintenant la performance globale du procédé long terme (si supposé centré donc!).
Nous avons:
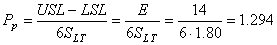 (74.97)
(74.97)
Mais avec un instrument ayant un 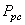 de
4, cela correspond réellement à: de
4, cela correspond réellement à:
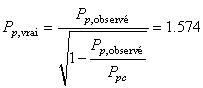 (74.98)
(74.98)
De plus, indiquons que comme nous savons faire un calcul d'intervalle de
confiance pour 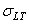 (voir
le calcul fait précédemment), il est alors aisé d'en avoir un pour (voir
le calcul fait précédemment), il est alors aisé d'en avoir un pour 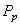 aussi! aussi!
Si l'analyse de la performance globale du procédé long terme est non centrée
(ce qui est le cas ici) nous utilisons donc:
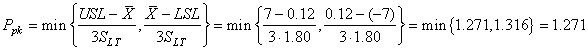 (74.99)
(74.99)
et nous savons encore une fois qu'à cause de l'instrument, cette valeur
est un peu sous-évaluée! Nous avons bien évidemment:
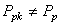 (74.100)
(74.100)
donc le processus n'est pas centré (on s'en doutait...). Alors, il
faut calculer la capabilité potentielle décentrée moyenne
long terme du procédé 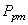 selon
les relations déterminées plus haut: selon
les relations déterminées plus haut:
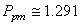 (74.101)
(74.101)
Bref, que ce soit de la valeur de 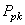 , ou ,
nous voyons que les valeurs sont toutes limites capables (c'est-à-dire
que la valeur est supérieure à 1 - voir définition plus
haut pour un rappel de ce que signifie "limite capable"). , ou ,
nous voyons que les valeurs sont toutes limites capables (c'est-à-dire
que la valeur est supérieure à 1 - voir définition plus
haut pour un rappel de ce que signifie "limite capable").
Si nous faisons alors nos calculs de PPM selon les relations obtenues
plus haut avec la valeur de 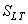 et
de et
de 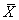 obtenues,
nous avons alors: obtenues,
nous avons alors:
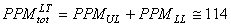 (74.102)
(74.102)
Ensuite, dire que ce chiffre est bon ou mauvais est difficile, car il
nous manque l'information de savoir quel est le coût de production, le coût
de revient et de réparation d'un produit et le tout est lui-même dépendant
de la quantité totale
fabriquée! Mais nous pouvons utiliser aussi le modèle de Taguchi
pour connaître
la valeur des paramètres (moments) calculés qu'il serait préférable
de ne pas dépasser!
Calculons maintenant les indices de capabilité court terme! Pour cela,
il nous faut l'estimateur de la moyenne de l'ensemble en considérant
chaque individu
comme une variable aléatoire. Nous savons (cf.
chapitre de Statistiques) que
cette moyenne est aussi la moyenne arithmétique dans le cas d'une loi
Normale et elle est strictement égale à celle que l'on calcule
en considérant
l'ensemble des individus comme une seule et unique variable aléatoire.
Donc, il vient que:
(74.103)
En ce qui concerne l'écart-type par contre ce n'est pas pareil. Mais
nous savons (cf. chapitre de Statistiques) que
la loi Normal est stable par la somme. Par exemple, nous avions démontré qu'étant
données deux variables aléatoires
indépendantes et distribuées selon une loi Normale (en imaginant
que chaque variable représente deux de nos dix échantillons),
nous avions pour leur sommee.:
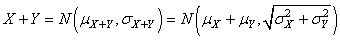 (74.104)
(74.104)
Or nous avons aussi démontré dans le chapitre de Statistiques que de par
la propriété de linéarité de l'espérance, nous avons:
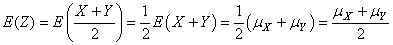 (74.105)
(74.105)
ce qui est conforme à notre remarque précédente pour la variance:
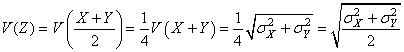 (74.106)
(74.106)
Donc in extenso:
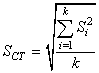 (74.107)
(74.107)
et dans notre cas particulier:
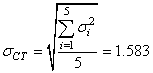 (74.108)
(74.108)
Donc l'erreur-standard (l'estimateur de l'écart-type de la moyenne) est de:
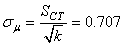 (74.109)
(74.109)
Donc l'intervalle de confiance à 95% de la moyenne est de (cf.
chapitre de Statistiques):
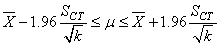 (74.110)
(74.110)
Soit dans notre cas:
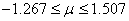 (74.111)
(74.111)
Nous remarquons donc qu'en court terme, l'intervalle est beaucoup plus large
qu'en long terme, ce qui est normal étant donné la faible valeur
de k (qui
vaut donc 5 dans notre exemple).
Et l'inférence statistique avec notre écart-type long terme utilisant le
test d'hypothèse bilatéral du donne
(cf. chapitre de Statistiques):
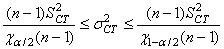 (74.112)
(74.112)
Ce qui nous donne dans notre cas:
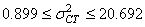 (74.113)
(74.113)
soit:
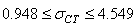 (74.114)
(74.114)
Nous remarquons alors que sur une analyse cours terme nous avons les intervalles:
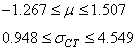 (74.115)
(74.115)
Les variations peuvent donc être énormes avec une probabilité cumulée
de 95% et il faudra prendre garde dans un cas pratique d'apporter des réglages
au plus vite afin de diminuer au maximum les moments!
Calculons maintenant la capabilité potentielle du procédé court terme (si
supposé centré donc!). Nous avons:
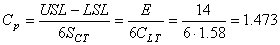 (74.116)
(74.116)
Donc, nous avons assez logiquement:
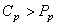 (74.117)
(74.117)
Mais avec un instrument ayant un de
4, cela correspond réellement à:
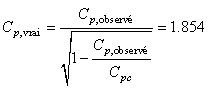 (74.118)
(74.118)
De plus, indiquons que comme nous savons faire un calcul d'intervalle de
confiance pour 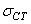 (voir
le calcul fait précédemment), il est alors aisé d'en avoir un pour (voir
le calcul fait précédemment), il est alors aisé d'en avoir un pour 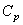 aussi! aussi!
Si l'analyse de la capabilité potentielle du procédé court terme est non
centrée (ce qui est le cas ici) nous utilisons donc:
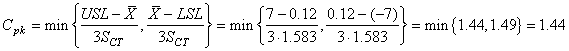 (74.119)
(74.119)
et nous savons encore une fois qu'à cause de l'instrument, cette valeur
est un peu sous-évaluée! Nous avons bien évidemment:
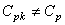 (74.120)
(74.120)
donc le processus n'est pas centré (on s'en doutait...). Alors, il
faut calculer la capabilité potentielle décentrée moyenne
court terme du procédé 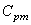 selon
les relations déterminées plus haut: selon
les relations déterminées plus haut:
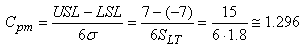 (74.121)
(74.121)
Bref, que ce soit de la valeur de 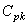 , ou ,
nous voyons que les valeurs sont toutes limites capables. , ou ,
nous voyons que les valeurs sont toutes limites capables.
Si nous faisons alors nos calculs de PPM selon les relations obtenues
plus haut avec la valeur de 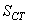 et
de obtenues,
nous avons alors: et
de obtenues,
nous avons alors:
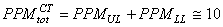 (74.122)
(74.122)
Ensuite, dire que ce chiffre est bon ou mauvais est difficile, car il
nous manque l'information de savoir quel est le coût de production, le coût
de revient et de réparation d'un produit et le tout est lui-même dépendant
de la quantité totale
fabriquée! Mais nous pouvons utiliser aussi le modèle de Taguchi
pour connaître
la valeur des paramètres (moments) calculés qu'il serait préférable
de ne pas dépasser!
Pour clore cette partie, voici la sortie d'un logiciel comme Minitab
15.1.1 dans lequel nous retrouvons tous les calculs effectués ci-dessus
plus
des cartes de contrôle dont nous ferons les démonstrations
détaillées
plus loin (se référer au chapitre de Statistiques
pour les dédtails concernant le test AD d'Anderson-Darling):

Figure: 74.9 - Analyse de capabilité Six Pack de Minitab 15.1.1
MODÈLE DE TAGUCHI
Dans le cadre des SPC (Statistical Process Control), il est intéressant
pour un industriel d'estimer les pertes financières générées
par les écarts à la
cible (attention on peut appliquer
également cette approche dans d'autres domaines que l'industrie!)
Nous pouvons avoir une estimation relativement simple et satisfaisante de
ses pertes (coûts) sous les hypothèses suivantes:
H1. Le processus est sous contrôle (écart-type constant) et suit une loi
de densité symétrique décroissante à gauche et à droite par rapport à la cible
(qui peut être une côte, un nombre d'erreurs par périodes, etc.)
H2. Le coût est nul lorsque la production (ou le travail) est centrée sur
la cible (minimum).
H3. Le coût augmente de manière identique lorsque la production se
décentre
sur la gauche et sur la droite (ce qui n'est par contre plus le cas dans le
domaine de l'administration par exemple). La fonction de coût
passe donc selon H2 et H3 par un minimum sur la cible.
Dès lors, si nous notons Y le décentrage par rapport à la cible T et L la
perte financière ("loss" en anglais d'où le L). Nous avons:
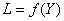 (74.123)
(74.123)
Même si nous ne connaissons pas la forme de cette fonction, nous pouvons
l'écrire sous forme de développement de Taylor (cf.
chapitre de Suites et Séries) autour de T tel
que :
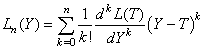 (74.124)
(74.124)
Si nous développons au troisième ordre:
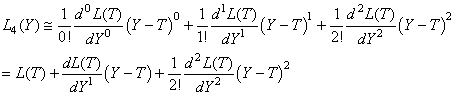 (74.125)
(74.125)
Or par l'hypothèse H2, nous avons L(T) qui est nul. Il reste
alors:
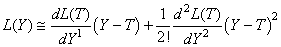 (74.126)
(74.126)
et comme par H3, la dérivée de la fonction L(Y) est nulle en T puisqu'il
s'agit d'un minimum alors:
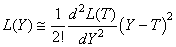 (74.127)
(74.127)
Ce qui est noté en SPC:
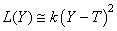 (74.128)
(74.128)
et est appelée "fonction de perte de Taguchi
(centrée)" ou
plus simplement "fonction perte de qualité (centrée)".
Bon c'est bien joli d'avoir cette relation mais comment doit-on l'utiliser?
Au fait, c'est relativement simple. Sous les hypothèses mentionnées plus
haut, si nous avons en production des mesures de défauts (côtes, retards, pannes,
bug, etc.) alors il suffit de calculer leur moyenne arithmétique 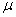 (estimateur
de la moyenne d'une loi Normale) et ensuite de savoir le coût financier ou
horaire L que
cela a engendré pour l'entreprise ou l'institution (parfois cette moyenne est
calculée
sur la base d'un unique échantillon...). (estimateur
de la moyenne d'une loi Normale) et ensuite de savoir le coût financier ou
horaire L que
cela a engendré pour l'entreprise ou l'institution (parfois cette moyenne est
calculée
sur la base d'un unique échantillon...).
Donc, la relation précédente devient:
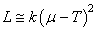 (74.129)
(74.129)
avec L et connus.
Et comme T est donné par les exigences du client ou du contexte alors
il est aisé d'obtenir
le facteur k:
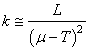 (74.130)
(74.130)
qui est au fait mathématiquement parlant
le point d'inflexion de la fonction mathématique L .
Cette dernière relation est parfois notée:
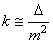 (74.131)
(74.131)
Une fois que nous avons k avec une bonne estimation, il est possible
de connaître L pour toute valeur Y et ainsi nous pouvons calculer
en production le coût d'une déviation quelconque par rapport à la cible.
Exemple:
Considérons une alimentation pour une chaîne stéréo
pour laquelle T vaut
110 [V]. Si la tension sort des 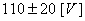 alors
la stéréo tombe en panne et doit être réparée.
Supposons que le coût de réparation
est (tous frais directs et indirects compris!) de 100.-. Alors, le coût associé pour
une valeur donnée
de la tension est: alors
la stéréo tombe en panne et doit être réparée.
Supposons que le coût de réparation
est (tous frais directs et indirects compris!) de 100.-. Alors, le coût associé pour
une valeur donnée
de la tension est:
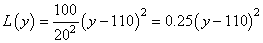 (74.132)
(74.132)
Voyons maintenant une manière élégante de calculer le coût moyen de Taguchi
(perte unitaire moyenne). Nous avons bien évidemment dans une chaîne de production
sur plusieurs pièces
d'une même famille:
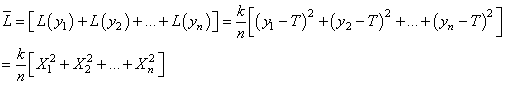 (74.133)
(74.133)
où les 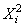 sont
des variables aléatoires normales (gaussiennes par hypothèse
car le procédé de fabrication est sous contrôle statistiques). Or, nous avons
démontré dans
le chapitre de Statistiques lors de notre étude de l'intervalle de confiance
sur la variance avec moyenne empirique connue que: sont
des variables aléatoires normales (gaussiennes par hypothèse
car le procédé de fabrication est sous contrôle statistiques). Or, nous avons
démontré dans
le chapitre de Statistiques lors de notre étude de l'intervalle de confiance
sur la variance avec moyenne empirique connue que:
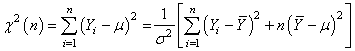 (74.134)
(74.134)
Donc:
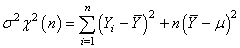 (74.135)
(74.135)
Dès lors:
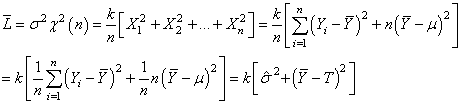 (74.136)
(74.136)
Cette dernière expression présente l'avantage
de montrer très
clairement que pour minimiser la perte, il faut agir sur la dispersion et l'ajustement
de la moyenne sur la valeur nominale.
Or nous avons démontré dans le chapitre de Statistiques que
(il est important dans les présents
développements
que nous utilisions les notations qui distinguent les différents estimateurs!):
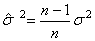 (74.137)
(74.137)
Donc:
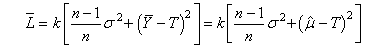 (74.138)
(74.138)
Et si n est grand, nous avons alors pour un lot de produits:
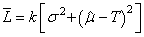 (74.139)
(74.139)
où le premier terme entre crochets représente donc la variance
de Y autour
de sa propre moyenne et le deuxième terme la déviation de Y par
rapport à la cible T.
Indiquons que l'on retrouve cette dernière relation dans la littérature et
dans les logiciels souvent sous la forme suivante:
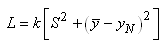 (74.140)
(74.140)
où l'indice N signifie "nominal". Évidemment,
quand la cible T (ou la valeur nominale) est prise comme étant nulle,
les relations se simplifient encore d'avantage.
Maintenant, rappelons les propriétés suivantes de l'espérance
et de la variance (cf. chapitre de Statistiques):
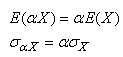 (74.141)
(74.141)
Dès, lors si le processus est décentré et que nous devons corriger
la variable aléatoire pour la recentrer, il vient intuitivement que ce facteur
sera alors:
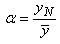 (74.142)
(74.142)
Dès lors, il vient immédiatement:
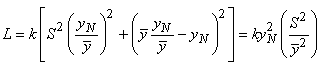 (74.143)
(74.143)
Donc pour minimiser L, sachant que les autres termes
sont imposés, il faut minimiser le rapport:
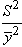 (74.144)
(74.144)
ou, ce qui revient au même, maximiser le rapport inverse
(qui reste sans dimensions):
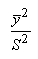 (74.145)
(74.145)
Ce nombre étant souvent très grand, il est d'usage
dans la littérature
et dans les logiciel de statistiques d'en prendre le logarithme en base 10
et de multiplier par 10 (c'est une idée inspirée de la physique
acoustique). Nous avons alors ce que nous appelons le rapport signal/bruit
(en anglais:
signal/noise), donné en décibels par:
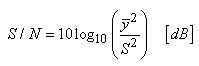 (74.146)
(74.146)
pour ce que les ingéieurs appellent "le
nominal est le meilleur".
Relation que l'on retrouve telle quelle dans un logiciel comme
Minitab lors de l'analyse de plans d'expérience de Taguchi (voir plus
loin ce que sont les plans d'expérience). Certains très rares
logiciels proposent également le cas particulier suivant: 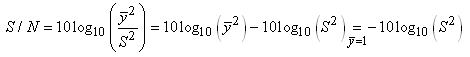 (74.147)
(74.147)
Pour la suite revenons à la relation:
(74.148)
Les ingénieurs parlent de minimiser la fonction perte
de qualité
quand T (la cible) doit est nul et donc qu'il faut minimiser tous
les 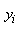 .
Donc la relation précédente se réduit finalement à: .
Donc la relation précédente se réduit finalement à:
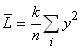 (74.149)
(74.149)
Ce que les ingénieurs aiment parfois bien résumer
sous la forme suivante (alors qu'à mon avis prendre le logarithme en
base 10 ainsi que de mettre un signe "-" dans ce cas ne se justifie
vraiment pas... bien au contraire):
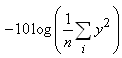 (74.150)
(74.150)
et même parfois il disent que c'est quand même un
rapport signal/bruit... alors que de toute évidence il n'y a aucun bruit
dans ce cas particulier qui est appelé: "le
plus petit est le meilleur" (PPEM). C'est exactement sous cette
forme que l'on peut trouver cet objectif écrit dans le logiciel Minitab.
Dans le cadre d'un paramètre à maximiser il est
d'usage de dire qu'on cherche alors plutôt à minimiser:
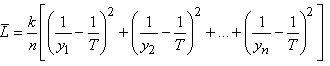 (74.151)
(74.151)
car vu que T tend vers l'infini il serait difficile
de faire quoi que ce soit mathématiquement parlant.
Donc justement vu
que T tend vers l'infini, cette dernière relation se réduit à: 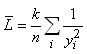 (74.152)
(74.152)
Ce que les ingénieurs aiment bien résumer parfois
sous la forme suivante ( ici le logarithme en base 10 se jusitife!):
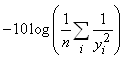 (74.153)
(74.153)
et même parfois il disent que c'est quand même un
rapport signal/bruit... alors que de toute évidence il n'y a aucun bruit
dans ce cas particulier qui est appelé: "le
plus grand est le meilleur" (PGLM). C'est exactement sous cette
forme que l'on peut trouver cet objectif écrit dans le logiciel Minitab.
Il est cependant, en étant malin, possible d'introduire le bruit dans la relation:
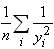 (74.154)
(74.154)
Pour cela écrivons:
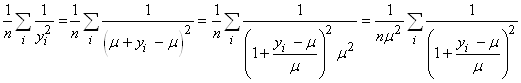 (74.155)
(74.155)
Posons:
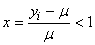 (74.156)
(74.156)
Alors dans ce cas, en utilisant la série de Taylor démontrée dans le chapitre
de Suies Et Séries:
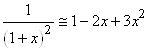 (74.157)
(74.157)
Nous avons alors:
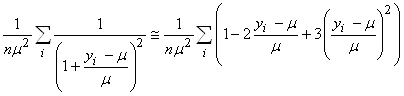 (74.158)
(74.158)
et sous contrôle statistique nous avons:
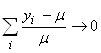 (74.159)
(74.159)
et en supposant que nous travaillons sur l'ensemble de la population de pièces,
nous avons:
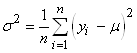 (74.160)
(74.160)
Il vient alors:
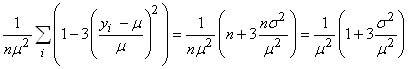 (74.161)
(74.161)
Donc au final en remplaçant un peu abusivement par les estimateurs, il vient:
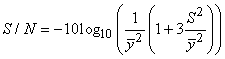 (74.162)
(74.162)
MAINTENANCE PRÉVENTIVE
L'évolution des techniques de production vers une plus grande robotisation
des systèmes techniques plus complexes a augmenté l'importance
de la fiabilité des machines de production. Aussi, un arrêt imprévu
coûte cher à une entreprise. De même, dans l'industrie aéronautique
et spatiale, les problèmes de fiabilité, de maintenabilité,
de disponibilité sont capitaux. La maintenance garantit le niveau de
fiabilité pour l'ensemble des composantes (mécaniques, électromécaniques
et informatiques).
L'existence d'un service de maintenance a pour raison le maintien des équipements
(systèmes) et aussi la diminution des pannes. En effet, ces dernières
coûtent cher, elles occasionnent:
- Des coûts d'intervention, de réparation
- Des coûts de non-qualité du produit
- Des coûts indirects tels que des frais fixes, pertes de production,
la marge bénéficiaire perdue...
De ce fait, il faut tout mettre en oeuvre pour éviter la panne, agir
rapidement lorsqu'elle survient afin d'augmenter la disponibilité du
matériel. Pour ce faire, il faut modéliser la vie des équipements.
L'ensemble des méthodes et techniques relatives à ses problématiques
sont habituellement classifiées sous le nom de "Analyse
des Modes de Défaillance, des Effets et de leur Criticité" AMDEC.
Nous distinguons principalement deux classes de systèmes: les systèmes
non réparables (satellites, bien de consommations à faibles coûts,
etc.) et les systèmes réparables (machines de production, moyens
de transports, etc.) où les approches théoriques sont différentes.
Pour la deuxième catégorie, il est possible d'utiliser aussi
les chaînes de Markov (où les états représenteront
le nombre de composants fonctionnels ou en panne d'un système conformément
à la norme ISO 31010), les réseaux
de Petri ou la simulation par Monte-Carlo.
L'idée est dans les textes qui vont suivre de faire un petit point
sur ces méthodes, d'en rechercher l'efficacité et de permettre
aux praticiens ingénieurs ou techniciens de mieux appréhender
ces problèmes. Une large place sera faite au modèle de Weibull,
qui a une implication importante dans le domaine.
OBSOLESCENCE PROGRAMMÉE
L'obsolescence programmée va à l'encontre de la maintenance préventive
dont le but premier est de fournir un produit de qualité et respectueux de
son environnement en connaissance précise de la durée de vie du produit et
du risque quantifiable de désuétude.
L'idée de l'obsolesence programmée est de réduire
la durée de vie ou d'utilisation d'un produit afin d'en
augmenter le taux de remplacement par le consommateur (stratégie parfois
motivée par les politiques...). La demande ainsi induite aurait pour but
(non démontré sur
le très
long terme...) de profiter au producteur, ou à ses
concurrents Le secteur bénéficie alors
d'une production plus importante, stimulant les gains de productivité (économies
d'échelle) et le progrès technique (qui accélère
l'obsolescence des produits antérieurs) et maintient l'emploi d'une
démographie toujours croissante est qui est donc problématique
par définition.
Le lecteur aura donc compris que je suis farrouchement contre ces méthodes
et que tout ingénieur et tout scientifique travaillant pour un entreprise
se doit de refuser par déontologie ce type de demande par la hiérarchie
quitte
à dénoncer ces méthodes anonymement sur Internet ou des
associations de consommateurs.
ESTIMATEURS EMPIRIQUES
Dans le cadre de l'étude de fiabilité non accélérée
(le vieillissement accéléré est un sujet trop complexe
pour être abordé sur ce site), nous sommes amenés à définir
certaines variables dont voici la liste:
- sera
le nombre d'éléments bons à sera
le nombre d'éléments bons à  (instant
initial) (instant
initial)
-  le
nombre d'éléments bons à le
nombre d'éléments bons à 
-  le
nombre d'éléments défaillants entre le
nombre d'éléments défaillants entre  et et  noté aussi noté aussi 
-  l'intervalle
de temps entre et . l'intervalle
de temps entre et .
Définitions:
D1. Nous définissons le "taux de défaillance
par tranche temporelle"  par
la relation: par
la relation:
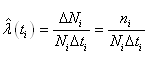 (74.163)
(74.163)
qui s'interprète donc comme étant le nombre d'éléments
défectueux par rapport au nombre d'éléments survivants
sur une tranche de temps donnée (il s'agit donc d'un pourcentage
de non-confirmités relatives par tranche temporelle).
Cette dernière relation est aussi parfois appelée "fonction
de hasard" ("hazard
ratio" (HR) en anglais) ou
"survie relative" et souvent notée  dans
la littérature anglophone. dans
la littérature anglophone.
D2. Nous définissons la "fonction de défaillance" par
la relation (densité de probabilité de défaillances à l'instant  ): ):
 (74.164)
(74.164)
en remarquant bien que le dénominateur n'est pas le même que
celui qui définit le taux de défaillance par tranche!
Cette fonction s'interprète donc comme étant le % d'éléments
défectueux dans la tranche de temps étudiée par rapport
au nombre total d'éléments initialement testés. Il
s'agit de l'indicateur qui intéresse le plus souvent l'ingénieur
car assimilable à une probabilité et ayant les propriétés d'une probabilité!
D3. Nous définissons naturellement la "fonction
de défaillance cumulée" par:
 (74.165)
(74.165)
que tend vers 1 lorsque le temps tend vers l'infini.
Cette fonction s'interprète donc comme étant le % d'éléments
défectueux cumulé par rapport au nombre total d'éléments
initialement testés. Il s'agit donc le fonction de répartition empirique
des probabilités de défaillance.
D4. Nous définissons in extenso la "fonction
de fiabilité" par (il s'agit du deuxième terme de la
précédente relation):
 (74.166)
(74.166)
Son nom provient par l'interprétation du rapport dans le cadre de la définition
de la fonction de défaillance cumulée.
Il faut se souvenir que la lettre R provient de l'anglais "reliability" qui
signifie "fiabilité" alors que le F en anglais
signifie "failure" qui
signifie en français "panne".
Par suite nous avons aussi:
 (74.167)
(74.167)
Cette dernière relation servant au calcul des lois de fiabilité!
Nous en déduisons un écriture qui permet parfois de mieux comprendre le
taux de défaillance par tranche temporelle. Effectivement:
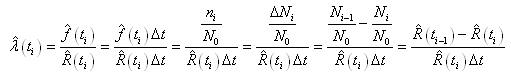 (74.168)
(74.168)
Puisque:
 et et  (74.169)
(74.169)
la fonction de défaillance peut être vue comme une probabilité comme
nous l'avons déjà mentionnée,
ce qui nous conduit à définir naturellement son espérance:
 (74.170)
(74.170)
Relation très utile dans la pratique qui donne en théorie le
pourcentage moyen d'éléments en panne à l'instant  . .
Donc pour résumer et avec les différentes notations que
nous pouvons trouver dans la littérature, cela donne (nous
verrons plus loin le même résumé dans le cas continu):

(74.171)
Signalons que nous verrons plus loin un modèle mathématique
statistique basé sur l'estimateur de Kaplan-Meier qui donne au fait
une estimation non paramétrique de la fonction de survie.
L'exemple qui suit va peut-être
vous aider à mieux
appréhender
le concept!
Exemple:
Nous avons relevé sur un lot de 37 moteurs d'un type donné les
défaillances suivantes répertoriées par tranches (données
par des clients ou mesurées en interne sur des bancs d'essais):
|
0 à
1'000 h.
|
1'000 à 2'000 h.
|
2'000 à
3'000 h.
|
3'000 à
4'000 h.
|
4'000 à
5'000 h.
|
5'000 à 6'000 h.
|
|
1 |
4 |
7 |
12 |
11 |
2 |
Tableau: 74.6
- Défaillances des moteurs par tranches d'effort
Il faut que nous estimions la valeur de la fonction de fiabilité  ,
la fonction de défaillance ,
la fonction de défaillance  et
la défaillance par tranche et
la défaillance par tranche  .
Les calculs sont élémentaires et nous obtenons le tableau
suivant: .
Les calculs sont élémentaires et nous obtenons le tableau
suivant:
| i |
Intervalle
d'observation |
Défaillances dans l'intervalle |
Survivants |
Cumul des
défaillants |
|

|

|
| 0 |
0 |
- |
37 |
0 |
100% |
0 |
0 |
| 1 |
0 à
1'000 h. |
1 |
36 |
1 |
97% |
2.7% |
(1/36)/1000=27.7 |
| 2 |
1'000 à
2'000 h. |
4 |
32 |
5 |
86% |
10.8% |
(4/32)/1000=125 |
| 3 |
2'000 à
3'000 h. |
7 |
25 |
12 |
67% |
18.9% |
(7/25)/1000=280 |
| 4 |
3'000 à 4'000
h. |
12 |
13 |
24 |
35.1% |
32.4% |
(12/13)/1000=923 |
| 5 |
4'000 à 5'000
h. |
11 |
2 |
35 |
5.4% |
5.4% |
(11/2)/1000=5500 |
| 6 |
5'000 à
6'000 h. |
2 |
0 |
37 |
0% |
- |
- |
Tableau: 74.7
- Analyse des défaillances des moteurs par tranches d'effort
Nous voyons ci-dessus par exemple que le taux de défaillance n'est
pas constant bien évidemment!
Le taux de panne serait
de l'ordre de 2.5 à 3% par an en 2013 pour les réfrigérateurs, lave-vaisselles,
etc. Pour le matériel audio-visuel il tournerait autour des 1.5 à 2% par
an.
Concernant les taux de défaillance, les ingénieurs reconnaissent
souvent trois tranches d'analyses suivant que certains objets étudiés
soient jeunes, en fonctionnement normal ou considéré en vieillissement.
On considère alors assez intuitivement (et parfois grossièrement) que le
taux de défaillance suit une courbe en baignoire comme représenté ci-dessous
(dans les tables techniques c'est souvent le taux de défaillance en fonctionnement
normal qui est donné):

Figure: 74.10 - Baignoire de la défaillance
alors que si vous observez le tableau précédent, le taux de
défaillance
ne suit pas du tout une courbe en baignoire (c'est donc un contre-exemple).
Les ingénieurs en fiabilité découpent souvent la baignoire
en trois parties visibles ci-dessus, mais sous la dénomination technique
suivante:
- D.F.R. pour "Decreasing Failure Rate":
les composants jeunes ayant des problèmes
de fabrication non identifiés lors de procédé sont éliminés
du lot ce qui a pour effet de diminuer le taux de défaillance. La loi
de Weibull est relativement bien adaptée pour modéliser cette
phase.
- C.F.R. pour "Constant Failure Rate":
les composants sont dans un état
stationnaire.
- I.F.R. pour "Increasing Failure Rate"
les composants sont en fin de vie et leur taux de défaillance augmente.
La loi de Weibull est à nouveau
relativement bien adaptée pour modéliser cette phase.
La loi de Poisson est relativement bien adaptée pour modéliser
les arrivées de pannes, et la loi exponentielle pour modéliser
le temps entre pannes successives. Ce constat découle de démonstrations
mathématiques disponibles dans le chapitre sur les Techniques De Gestion
(théorie des files d'attentes). Donc, cela signifie que pannes sont
souvent considérrées comme indépendantes.
Dès lor, la loi sur le nombre de pannes dans une période donnée
est alors une loi "sans mémoire" et on peut modéliser
par une loi de Poisson (démonstration aussi faite dans le chapitre sur les
Techniques De Gestion).
Remarque: Contrairement
à ce que pas mal de théoriciens pensent..., les logiciels informatiques
grand public ont aussi leur taux de défaillance qui suit une courbe
en baignoire. Effectivement, au début il y a des bugs non détectés
qui font que la défaillance va diminuer
au fur et à mesure de leur détection et leur correction. Ensuite,
à
cause
des mises à jour fréquentes de l'environnement qui ont tendance à rajouter
d'autres problèmes (service pack), le taux de défaillance se
maintient à peu
près constant. Enfin, avec le temps, l'évolution des
technologies
environnantes (framework) rendent l'applicatif obsolète et des fonctions
ne répondent ou n'agissent plus correctement ce qui fait à nouveau
augmenter le taux de défaillance.
Vis-à-vis de l'efficacité de la rénovation, indiquons qu'elles peuvent (en
simplifiant) très fréquemment se ranger en trois catégories:
1. "As good as new": C'est de la maintenance
préventive
dans le sens que nous changeons une pièce lorsque sa durée de
vie l'amène à un
taux de défaillance
que nous considérons comme trop élevé et dont la rupture
non anticipée coûtera
plus cher que sa non-anticipation.
2. "As bad as old": C'est de la maintenance
déficiente dans
le sens que nous changeons une pièce que lorsqu'elle est arrivée à rupture,
ce qui engendre majoritairement des coûts d'arrêts plus élevés
que la maintenance préventive qui consiste elle à anticiper
au plus juste la casse.
3. "Restauration partielle": C'est
de la maintenance préventive
minimale dans les sens que nous réparons la pièce défaillante
plutôt que de la remplacer
par une nouvelle. À nouveau le problème du coût doit être calculé en
faisant un audit des besoins et des délais de l'entreprise.
Revenons-en à d'autres définitions au passage à la limite
du continu.
Nous savons donc que le "taux de défaillance
instantané" aura
pour unité l'inverse du temps tel que  .
Ce taux est, dans le cadre de notre étude, pas nécessairement
constant dans le temps comme nous avons pu le constater! .
Ce taux est, dans le cadre de notre étude, pas nécessairement
constant dans le temps comme nous avons pu le constater!
Soit R(t) le pourcentage cumulé d'objets analysés
toujours en état de bon fonctionnement d'un échantillon testé au temps t.
Le nombre d'objets tombant en panne durant le temps infinitésimal dt est
donc égal à:
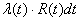 (74.172)
(74.172)
ce qui correspond donc à la diminution du stock initial en bon fonctionnement
au temps t.
Nous pouvons alors écrire la relation:
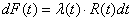 (74.173)
(74.173)
soit:
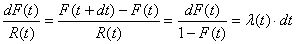 (74.174)
(74.174)
Que l'on retrouve souvent dans la littérature sous les formes équivalentes
suivantes:
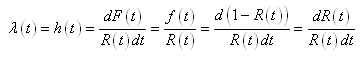 (74.175)
(74.175)
Définition: La "probabilité conditionnelle
de défaillance" entre t et t + dt est
définie comme probabilité conditionnelle temporelle de
connaître
l'événement à un instant t donné,
sachant que nous ne l'avons pas connu avant et que nous avons donc
survécu jusqu'à l'instant t (et elle ne fait
que d'augmenter avec le temps in extenso...):
 (74.176)
(74.176)
où F(t) et R(t) sont, pour
rappel, respectivement la fonction de probabilité cumulée
de défaillance (probabilité cumulée
de tomber en panne au temps t) et la fonction de probabilité cumulée
fiabilité appelée également "fonction
de survie". R(t) valant 1 au temps 0 et...
0 après
un temps infini comme nous l'avons déjà vu avant!
Nous reviendrons sur cette approche conditionnelle plus en détail avec
une aproche beaucoup plus pédagogique lors de notre étude du modèle de
hasard proportionnel de Cox plus bas.
Remarque: Par
la même démarche intellectuelle, plutôt que de définir
une fonction de défaillance F(t) et de survie R(t)
avec sa fonction de risque, nous pouvons définir une fonction de réparabilité avec
sa fonction de M(t) qui serait alors une "fonction
de maintenabilité".
Si nous intégrons (attention u représente maintenant
le temps!):
 (74.177)
(74.177)
Comme  nous
avons: nous
avons:
 (74.178)
(74.178)
d'où:
 (74.179)
(74.179)
Par ailleurs, puisque nous avons vu que  ,
nous avons alors la "fonction de densité/répartition
de défaillance instantanée": ,
nous avons alors la "fonction de densité/répartition
de défaillance instantanée":
 (74.180)
(74.180)
Nous pouvons obtenir cette relation et interprétation sous une autre
manière:
 (74.181)
(74.181)
où nous retrouvons donc F(t) la fonction de probabilité cumulée
de défaillance. Évidemment pour déterminer la loi f(t),
nous utilisons les outils statistiques d'ajustements habituels (cf.
chapitre de Statistiques).
Nous avons alors la relation très importante (voir la plus importante!)
dans la pratique qui relie la loi de densité de la défaillance instantanée
et la loi de fiabilité:
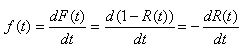 (74.182)
(74.182)
Nous avons ci-dessus les trois expressions les plus générales
liant les lois de fiabilité et le taux instantané de défaillance.
Ajoutons encore que nous avons la fonction de hasard instantée suivante
qui en découle:
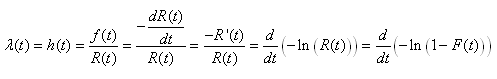 (74.183)
(74.183)
Il s'ensuit alors immédiatement que:
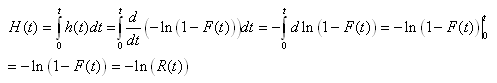 (74.184)
(74.184)
Puisque f(t) est la fonction de densité de défaillance,
l'espérance mathématique
de la défaillance est alors donnée par:
 (74.185)
(74.185)
Ainsi, si la répartition des pannes est équiprobable (fonction
de densité uniforme), ce qui est plutôt rare, la moitié des équipements
seront hors service à E(t).
Remarque: En
observant 100'000 disques durs, des ingénieurs de Google
auraient observé en moyenne 8% de pertes par an! Donc un taux de perte
plus élevé que celui qu'aurait. annoncé des fabricants
qui serait d'environ 300'000 heures! Le taux de perte est plus élevé les
3 premières années! Mais peut-être que les disques qui
survivent vivent plus longtemps!
Nous
avons aussi en utilisant l'intégration par parties et la relation précédente:

D'où une autre manière de l'exprimer:
 (74.186)
(74.186)
Nous avons donc la relation:
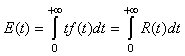 (74.187)
(74.187)
Donc pour résumer et avec les différentes notations que
nous pouvons trouver dans la littérature, cela donne:

(74.188)
Signalons encore une fois (!) que nous verrons plus loin un modèle
mathématique
statistique basé sur l'estimateur de Kaplan-Meier qui donne au fait
une estimation non paramétrique de la fonction de survie.
Avant de continuer donnons quelques définitions d'indicateurs de maintenance
dont les plus importantes sont dans la norme européenne de maintenance
NF EN 13306:2010 (je précise
car
on trouve sur le web
le pire et le meilleur concernant les définitions de ces indicateurs...):
- La T.B.M ou "Time
Between Maintenance" est le temps contractuel entre deux
visites ou contrôle de maintenance (non défini dans la norme).
- La M.O.T.B.F. ou "Mean
Operating Time Between Failures" applicable uniquement pour
des éléments
réparables est l'espérance mathématique du temps opérationnel
d'un système entre la fin de la première défaillance
et le début de la prochaine (défini dans la norme). Dans
l'industrie la M.O.T.B.F. est aussi notée M.U.T. pour "Mean
Up Time".
- La M.T.B.F. ou "Mean
Time Between Failures" applicable uniquement pour des éléments
réparables est l'espérance mathématique du temps opérationnel
d'un système entre le début de deux défaillances (défini
dans la norme). Cet indicateur inclut donc les temps de non-fonctionnement.
Dans
le domaine des services, la M.T.B.F. est parfois
notée M.T.B.S.A pour "Mean Time Between System Accidents".
Dans le domaine des lignes de production la M.T.B.F. est notée M.T.B.D. pour
"Mean Time Between Defects" (on arrête pas la production
parce que l'on a détecté
un défaut conformément à ce que nous verrons les de
notre étude des cartes
de contrôle). Dans le domaine de l'informatique la M.T.B.F. est notée M.T.B.E. pour "Meat
Time Between Errors" (on arrête rarement un logiciel ou un site
web parce que l'on y a détecté une erreur!).
- La M.T.T.F. ou "Mean
Time To Failure" applicable pour des éléments
réparables ou non est l'espérance mathématique du temps
opérationnel
d'un système jusqu'à sa première panne (non défini
dans la norme). Au fait c'est ce dernier que l'on calcule le plus souvent
dans les laboratoires de tests.
- La M.R.T. ou "Mean
Repair Time" applicable uniquement pour des éléments
réparables est l'espérance mathématique du temps de
réparation (défini dans la norme).
- La M.T.T.R ou "Mean
Time To Restore" applicable
uniquement pour des éléments réparables est l'espérance
mathématique du temps de redémarrage (défini
dans la norme). Dans le domaine des services, la M.T.T.R. est
parfois notée M.T.T.R.S. pour "Mean
Time To Restore Service".
- La M.D.T. ou "Mean
Down Time" est égale à l'espérance mathématique du temps pendant
lequel le système
n'est pas opérationnel.
Cet indicateur (non défini dans la norme) inclus donc la M.R.T. Il
en découle que la M.T.B.F est égale à la somme de la M.O.T.B.F. (M.U.T.)
et la
M.D.T.
- La M.T.T.D. ou "Mean
Time To Detection" est égale à l'espérance
mathématique du temps pendant lequel le système n'est pas été
détecté comme étant non opérationnel. Cet indicateur
(non défini dans la norme), au même titre que la
M.R.T., est inclus dans la M.D.T.
- La M.T.T.A. ou "Mean
Time to Answer" est égale à l'espérance
mathématique du temps pendant lequel l'utilisateur a attendu une réponse
ou intervention du fabricant après avoir signalé une panne. Cet
indicateur (non défini
dans la norme), au même titre que la M.R.T. et la M.T.T.D., est inclus
dans la M.D.T.
- Le T.R.S. ou "Taux
de Rendement Synthétique" dans le domaine de la
maintenance est défini traditionnellement comme étant simplement
le rapport entre le temps de fonctionnement opérationnel et
le temps attendu de fonctionnement opérationnel (non
défini dans la norme).
- Le S.A. ou "Service
Ability" qui dans le domaine de la maintenance
est souvent donné par les deux relations suivantes et dont le but est
qu'il soit le plus proche possible de 1 (c'est-à-dire de faire tendre
vers zéro la M.D.T.).:
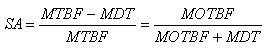 (74.189)
(74.189)
et on peut en définir encore beaucoup d'autres en dehors de la norme...
Voici un schéma qui résume peut-être un peu mieux tout
cela:

Figure: 74.11 - Résumé des indicateurs de fiabilité les plus importants
Remarques:
R1. Pour chacun de ces indicateurs on
indiquera s'il a été pris en
compte des causes extérieures ou non.
R2. Si la taille du lot testée est très petite, il est d'usage
d'utiliser la moyenne arithmétique comme estimateur de l'espérance.
Évidemment cela peut amener à de grossières erreurs...
R3. Il est bien évidemment possible à partir des indicateurs
définis de
calculer si une machine (élément) est apte à garantir
le service souhaité
(comme par
exemple
un nombre
de pièces par année à fabriquer!). Donc non seulement
ces indicateurs peuvent
être mesurés, mais ils peuvent donc aussi être utilisés
pour vérifier l'atteinte
d'un objectif souhaité!
R4. En ce tout début de 21ème siècle les pays devraient
en toute rigueur légiférer pour obliger tous les industriels à communiquer
la M.T.T.F. de leurs produits afin que le consommateur puisse mieux faire
son choix à l'achat et comparer les valeurs par rapport à la
garantie fournie! Malheureusement, ce n'est pas le cas et cela permettrait
de mettre en évidence une mauvaise tradition actuelle dans l'industrie
des produits grand public qui est de fabriquer des composants dont la durée
de vie tourne autour des 200'000 heures afin d'assurer aux industriels un
renouvellement de leur marché.
Exemple:
Une machine est censée travailler 24 heures sur 24,
7 jours sur 7. Elle a tourné jusqu'à aujourd'hui pendant 5'020
heures mais avec 2 arrêts d'un total de 20 heures (donc inclus dans les
5'020 [h]). Donnez les indicateurs classiques relativement au peu
d'informations communiquées:
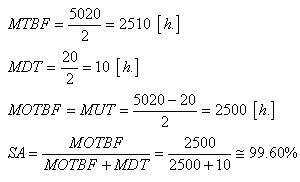 (74.190)
(74.190)
La classification des systèmes en terme de disponibilité conduit
communément à 7 classes de non prise en compte (système
disponible 90% du temps, et donc indisponible plus d'un mois par an) à ultra
disponible (disponible 99.99999% du temps et donc indisponible seulement
3 secondes par an): ces différentes classes correspondent au nombre
de 9 dans le pourcentage de temps durant lequel les systèmes de
la classe sont disponibles (une année comporte 525'600 minutes):.
|
Indisponibilité
(minutes par an)
|
Pourcentage disponibilité
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
très grande haute disponibilité
|
|
|
|
Tableau: 74.8
- Classes de défaillances AMDEC
L'usage de ces paramètres dans le cadre de fiabilité font
dire que nous avons une "approche en valeurs moyennes".
Attention cependant à une chose! Ce n'est pas parce qu'un
événement à une probabilité plus petite ou infiniment plus petite qu'une
autre qu'il en est moins important!! Effectivement il faut bien évidemment
pendre en compte (de façon certes un peu empirique) la gravité de la défaillance.
Ainsi, une centrale nucléaire à beau être peut-être 1'000 fois plus sûre
qu'une central thermique en termes de probabilités... il n'en est rien
en termes de gravité lorsqu'un défaillance majeure se produit! Effectivement
dans le cas d'une central thermique il peut y avoir au pire 500 personnes
touchées alors qu'avec une centrale nucléaire c'est une autre
histoire...
Signalons enfin un cas simple: Certains composants (électroniques
typiquement) ont dans leur période de maturité un taux de
défaillance constant. La loi de
probabilité cumulée de la défaillance qui en découle
s'en déduit alors immédiatement puisque la fonction de hasard
instantanée est donnée par  : :
 (74.191)
(74.191)
Indiquons que nous retrouvons très souvent cette dernière relation sous
la forme suivante dans la littérature:
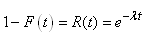 (74.192)
(74.192)
et donc nous avons bien:
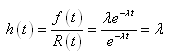 (74.193)
(74.193)
Soit pour résumer un peu pour la loi exponentielle:
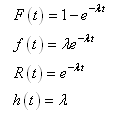 (74.194)
(74.194)
Les fonction de hasard et de survie sont alors graphiquement
de la forme suivante:

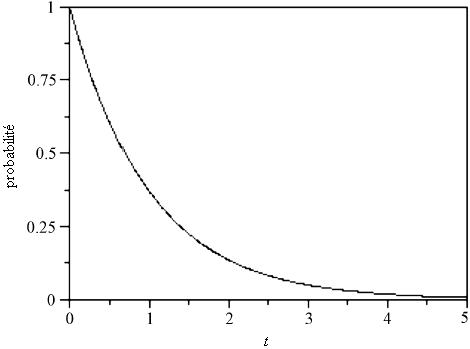
Figure: 74.12 - Plot de la fonction de hasard et de survie de la loi exponentielle
La fonction de densité des éléments défaillants
au temps t est alors:
 (74.195)
(74.195)
Elle suit donc une loi exponentielle! Cette loi et ses moments nous sont
connus (cf. chapitre de Statistiques). Il devient
alors facile déterminer le M.T.T.F. et son écart-type
(inverse du taux de défaillance) ainsi qu'un intervalle de confiance.
Par ailleurs, si nous calculons la fiabilité R(t)
au temps correspondant à la M.T.T.F. (inverse du taux de défaillance
dans le cas de la loi exponentielle) nous obtiendrons toujours une probabilité cumulée
de 36.8% (donc en gros une chance sur trois de fonctionner à ce moment
là et 2 chances sur 3 de tomber en panne) et non de 50% comme on peut
le penser intuitivement (ce qui est le cas seulement si la loi de probabilité est
symétrique).
Étant donné que les tables techniques de fiabilité dans
l'industrie supposent presque toujours le taux de fiabilité constant
alors nous comprenons mieux l'importance de celle-ci (nous en aurons un exemple
lors
de notre présentation des topologies de systèmes).
Rappelons aussi que nous avons vu dans le chapitre de Probabilités
que si nous avons un ensemble d'événements indépendants
(mécanismes indépendants) avec une probabilité donnée,
alors les probabilités calculées sur l'ensemble dans sa totalité implique
la multiplication des probabilités.
Donc dans un mécanisme ayant des pièces indépendantes
mais essentielles (système dit en "série") la fonction
de densité de fiabilité globale sera égale à la
multiplication des lois de probabilités cumulées R(t)
et ce qui équivaut donc dans le cas d'une loi exponentielle d'avoir
une seule loi exponentielle dont le taux de défaillance global est égal à la
somme des taux de défaillance des différentes pièces.
Un autre exemple: En mécanique, où le phénomène d'usure
est à l'origine de
la défaillance, le taux de défaillance est souvent du type linéaire
(il augmente donc de manière constante avec le temps et est non nul
lors du premier allumage de l'appareil):
 (74.196)
(74.196)
Alors:
 (74.197)
(74.197)
Soit:
 (74.198)
(74.198)
Comme (pour un matériel dont le temps de réparation est négligeable):
 (74.199)
(74.199)
cette intégrale ne peut se calculer que par une méthode
numérique.
Dès
lors on préfère prendre des lois rapprochées à l'aide
d'ajustement du Khi-deux, comme par exemple la loi de Weibull, qui est
un peu la poubelle à tout mettre dans le domaine...
Il faut savoir que dans les banques de données de fiabilité communes
et gratuitement disponibles sur le marché sont normalement donnés:
la dénomination du matériel ou du composant, la MTBF, la taux
de défaillance moyen, le patrimoine statistique, un coefficient multiplicatif
du taux de défaillances dépendant de l'environnement ou des contraintes
d'utilisation.
MODÈLE DE WEIBULL
Encore une fois, les techniques de maintenances utilisent les probabilités
et statistiques donc nous renvoyons le lecteur au chapitre du même nom.
Cependant, il existe dans le domaine de la maintenance (et pas seulement) une
fonction de densité de probabilité très utilisée
appelée "loi de Weibull".
Elle serait complètement empirique et est définie par:
 (74.200)
(74.200)
où  avec avec  qui
sont respectivement appelés "paramètre
d'échelle" qui
sont respectivement appelés "paramètre
d'échelle"  , "paramètre
de forme" , "paramètre
de forme"  et "paramètre
d'emplacement" et "paramètre
d'emplacement"  . .
Remarque: Les ingénieurs dans les entreprises doivent obligatoirement se référer
à la norme CEI 61649 Analyse de Weibull pour en faire
usage de manière standardisée!
La loi de Weibull est aussi souvent notée sous la forme suivante en
posant  , ,  , ,  (dans
ce cas le paramètre d'emplacement est implicitement posé comme étant nul): (dans
ce cas le paramètre d'emplacement est implicitement posé comme étant nul):
 (74.201)
(74.201)
Elle peut être calculée dans la version française
de Microsoft Excel 11.8346 sous cette dernière forme en utilisant
la fonction LOI.WEIBULL( ).
Remarque: Elle
peut être vue comme une généralisation de la fonction de
distribution exponentielle (nous allons voir plus loin pourquoi!) avec l'avantage
qu'il est possible de jouer avec les trois paramètres de manière à obtenir
presque n'importe quoi.

Figure: 74.13 - Fonctions de densité et de distribution de Weibull pour différentes
valeurs
de
alpha (source: Wikipédia)
En annulant le paramètre d'emplacement ,
nous obtenons la "distribution de Weibull à deux
paramètres":
 (74.202)
(74.202)
qui a une application pratique importante et dont nous avons calculé les estimateurs
des paramètres dans le chapitre de Statistiques.
En posant encore une fois  et
en assumant que et
en assumant que  nous
avons la "distribution de Weibull à un paramètre" (c'est
un peu idiot comme définition mais bon...): nous
avons la "distribution de Weibull à un paramètre" (c'est
un peu idiot comme définition mais bon...):
 (74.203)
(74.203)
où le seul paramètre inconnu est le paramètre d'échelle  .
Nous assumons que le paramètre .
Nous assumons que le paramètre  est
connu a priori d'expériences passées sur des échantillons
identiques. Remarquons que la fonction de distribution de Weibull à un
paramètre
est la dérivée de la fonction de répartion (probabilité cumulée)
suivante (il y a trois dérivées intérieurs successives
pour retomber sur la fonction de distribution... ce qui constitue un bon exemple
de ce que nous
avons vu dans le chapitre de Calcul Différentiel Et Intégral): est
connu a priori d'expériences passées sur des échantillons
identiques. Remarquons que la fonction de distribution de Weibull à un
paramètre
est la dérivée de la fonction de répartion (probabilité cumulée)
suivante (il y a trois dérivées intérieurs successives
pour retomber sur la fonction de distribution... ce qui constitue un bon exemple
de ce que nous
avons vu dans le chapitre de Calcul Différentiel Et Intégral):
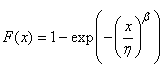 (74.204)
(74.204)
Il s'ensuit alors dans l'ingénierie de la faibilité que dans ce cas particulier,
nous avons alors:
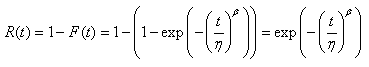 (74.205)
(74.205)
Nous retrouvons également parfois cette relation dans la littérature
sous la forme:
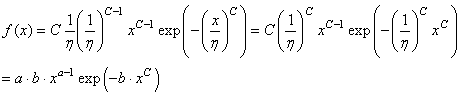 (74.206)
(74.206)
Remarquons que si est
égal à l'unité, nous retrouvons alors une loi exponentielle
d'espérance
:
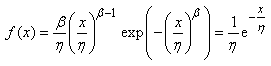 (74.207)
(74.207)
La MTBF est alors donnée par l'espérance de la loi de Weibull
avec non
nul:
 (74.208)
(74.208)
Posons:
 (74.209)
(74.209)
avec:
 (74.210)
(74.210)
Ce qui donne:
 (74.211)
(74.211)
La première intégrale nous est déjà connue, nous
l'avons déjà vue dans le chapitre de Calcul Différentiel.
Il s'agit de la fonction gamma d'Euler:
 (74.212)
(74.212)
Nous avons finalement:
 (74.213)
(74.213)
En annulant paramètre d'emplacement  il
vient le cas courant en fiabilité: il
vient le cas courant en fiabilité:
 (74.214)
(74.214)
Remarque: Si
par le plus grand des hasards  ,
alors comme nous l'avons démontré lors de notre étude
de la fonction Gamma d'Euler:
 (74.215)
(74.215)
Dans le cas où  il
faut faire appel aux tables numériques obtenues par les algorithmes
vus dans le chapitre de Méthodes Numériques. il
faut faire appel aux tables numériques obtenues par les algorithmes
vus dans le chapitre de Méthodes Numériques.
De même:
 (74.216)
(74.216)
Finalement lorsque paramètre d'emplacement est nul, il vient:
 (74.217)
(74.217)
Remarque: Certains
spécialistes, lorsqu'il est fait usage des deux moments d'ordre deux dans
l'analyse probabiliste de la défaillance, parlent parfois "d'approche
en moyenne quadratique"...
Pour clore, signalons qu'il est d'usage de considérer 5 situations
importantes et pertinentes de la loi de Weibull en fonction des valeurs de
ses paramètres
1. La fonction de densité de survie ressemble à une décroissance
exponentielle et dès lors, la fonction de risque (taux de défaillance)
est élevée au départ et diminue au fil du temps (première
partie en forme de "baignoire" de la fonction de risque). Il
s'agit typiquement d'une situation où les défaillances sont
précoces
car les défaillances se produisent dans la période initiale
de la vie du produit.
2. La fonction de densité de survie ressemble à une décroissance
exponentielle. Dès lors, le risque de
défaillance est constant au cours de la vie de la pièce (deuxième
partie en forme de "baignoire" de la fonction de risque). Il
s'agit typiquement d'une situation où les défaillances sont
aléatoires
et sources de multiples causes. Dans cette situation, la loi de Weibull
modélise
la phase de "vie utile" du produit.
3. La fonction de densité de survie s'élève jusqu'à un
sommet puis décroît avec une asymétrie assez prononcée
(densité forte à gauche) et dès lors, la fonction
de risque (taux de défaillance) augmente rapidement au début
et finit par se stabiliser. Il s'agit typiquement d'une situation où l'usure
initiale est très rapide.
4. La fonction de densité de survie s'élève jusqu'à un
sommet puis décroît avec faible asymétrie assez (densité un
peu plus élevée à gauche) et dès lors, la fonction
de risque (taux de défaillance) augmente de manière linéaire.
Il s'agit typiquement d'une situation où le risque de défaillance
est dû à l'usure et augmente de façon constante au
cours de la durée de vie du produit.
5. La fonction de densité survie ressemble à une gaussienne
large et la fonction de risque (taux de défaillance) croît
rapidement (croissance de type exponentielle). Il s'agit typiquement de
la situation
où l'on
arrive à la fin de la vie d'un ensemble de pièces (troisième
partie en forme de "baignoire" de la fonction de risque).
Voici quelques exemples types de fonction de risque (hasard) de Weibull:
Figure: 74.14 - Plot de 4 fonctions de hasard de Weibull pour différentes valeurs des
paramètres
avec les fonctions de survie correspondantes:
Figure: 74.15 - Plot de 4 fonctions de survie de Weibull pour différentes valeurs
des
paramètres
Pour résumer nous avons donc pour la loi de Weibull à deux paramètres:
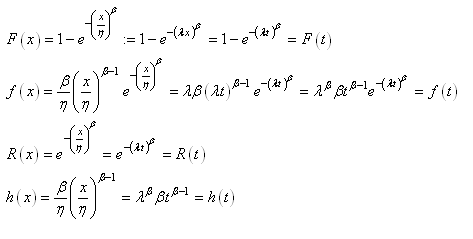 (74.218)
(74.218)
Nous voyons donc bien que si 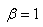 nous
retrouvons toutes les fonctions du cas se basant sur la loi exponentielle. nous
retrouvons toutes les fonctions du cas se basant sur la loi exponentielle.
Exemple:
Un constructeur de voiture connaît la distribution du temps jusqu'à la
première
panne d'un de ses véhicules dans des conditions moyennes de conduite.
La fonction de répartition de Weibull obtenue de par les essais est
fonction de Weibull à deux paramètres donnée par:
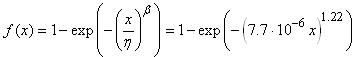 (74.219)
(74.219)
où x est la distance parcourue un kilomètres
des véhicules tests.
Si nous voulons trouver la garantie en kilomètres englobant 5%
des véhicules, nous devons alors résoudre l'équation:  (74.220)
(74.220)
Soit avec un peu d'algèbre élémentaire:
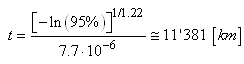 (74.221)
(74.221)
TOPOLOGIE DES SYSTÈMES
Lorsque nous travaillons avec des systèmes réels non réparables
(mécaniques, électroniques
ou autres), nous sommes confrontés à des contraintes différentes
suivant le type de montage que nous avons. L'étude de ce type de systèmes
est aussi appelée "Reliability Block Diagramm".
Les deux hypothèses principales de l'étude de ces systèmes sont:
H1. La panne d'un composant est indépendante des autres
H2. Pas de pannes arrivant conjointement
Nous reconnaissons 5 topologies principales dont chaque composant est représenté
par un bloc:
T1. Topologie série:
Si un seul composant est défectueux le système ne fonctionne plus (les exemples
sont tellement nombreux et simples à trouver que nous n'en citerons pas).
Alors dans l'hypothèse où la panne d'un composant est indépendante des autres,
la probabilité cumulée de défaillance est égale au produit des probabilités
cumulées (cf. chapitre de Probabilités).

Figure: 74.16 - Topologie série
Dans le cadre des arbres de défaillance probabilistes (voir plus
bas), cette topologie correspond à une porte OU (OR)
avec n entrées car il suffit qu'un des blocs soit en panne
pour que la sortie ne fonctionne plus:
Figure: 74.17 - Porte OU (OR)
Comme souvent il est fait usage de la loi exponentielle, la multiplication
de plusieurs termes de probabilités cumulées étant relativement longue à écrire,
nous lui préférons l'utilisation de la probabilité de fiabilité cumulée R.
Ainsi, la fiabilité (probabilité de fonctionnement) d'un système
série
est donnée
par:
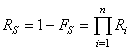 (74.222)
(74.222)
Ce qui nous amène bien à une valeur nulle pour la fiabilité si
au minimum un bloc a une fiabilité nulle.
Ce qui se note traditionnellement dans le domaine:
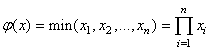 (74.223)
(74.223)
Remarque: Le lecteur attentif aura remarqué que
le système série est toujours moins fiable que sa composante
la moins fiable!
Attention!! Dans le cas des composantes électroniques, le taux de défaillance
est souvent considéré comme constant par souci de simplification et la fonction
de densité est alors celui de la loi exponentielle:
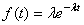 (74.224)
(74.224)
Or, nous avons démontré que dans le cas d'un système non réparable:
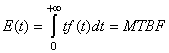 (74.225)
(74.225)
Et comme nous avons démontré dans le chapitre de Statistiques
que l'espérance
de la loi exponentielle est:
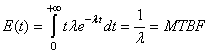 (74.226)
(74.226)
Nous avons aussi démontré plus haut que:
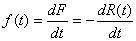 (74.227)
(74.227)
Donc:
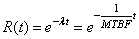 (74.228)
(74.228)
Alors pour un système série à taux de défaillance constant:
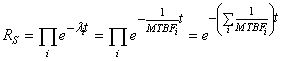 (74.229)
(74.229)
Ainsi, dans ce cas particulier:
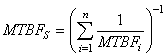 (74.230)
(74.230)
ou autrement écrit:
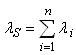 (74.231)
(74.231)
et... le problème sur Internet c'est que les pages web qui parlent
de systèmes à topologie
série (ou parallèle) font implicitement usage d'une loi exponentielle,
d'où parfois
de grosses erreurs de la part des praticiens qui utilisent cette dernière
relation sans avoir étudié les détails mathématiques
sous-jacents.
T2. Topologie parallèle:
Contrairement au système précédent, le système continue à fonctionner
si au moins un composant fonctionne (typiquement les systèmes de redondance
dans les avions, les fusées ou les centrales nucléaires).

Figure: 74.18 - Topologie parallèle
Dans le cadre des arbres de défaillance probabilistes (cf.
chapitre Techniques De Gestion), cette topologie correspond à une
porte ET (AND) avec n entrées car il faut que tous les blocs
soient en panne pour que la sortie ne fonctionne plus:
Figure: 74.19 - Porte ET (AND)
En d'autres termes, il s'arrête de fonctionner si et seulement si:
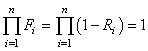 (74.232)
(74.232)
Donc, il vient immédiatement que:
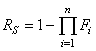 (74.233)
(74.233)
Remarque: En gestion de projets ce type de structure parallèle
est typiquement utilisée lorsque l'on souhaite connaître la fiabilité totale
de plusieurs
fournisseurs de pièces identiques (comme cela si l'un d'eux à des retards
ou autres problèmes, les autres doivent permettre d'atténuer l'impact négatif)
en connaissant ou en estimant bien évidemment la fiabilité de chacun...
Obervons (utile pour plus tard) que dans le cas très particulier
où
la fiabilité de tous les éléments est égale,
nous avons:
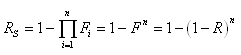 (74.234)
(74.234)
Nous avons donc pour le système parallèle dont les composantes sont à taux
de défaillance constant et tous identiques (pour simplifier l'étude):
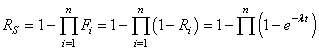 (74.235)
(74.235)
Nous avons alors:
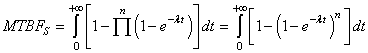 (74.236)
(74.236)
En posant:
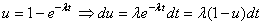 (74.237)
(74.237)
et en remplaçant dans l'expression antéprécédente, nous
avons:
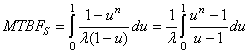 (74.238)
(74.238)
Il n'est pas possible d'intégrer cette dernière relation de
manière formelle,
mais si on compare pour différentes valeurs de n fixées
alors nous voyons très vite que:
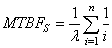 (74.239)
(74.239)
ou autrement écrit:
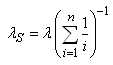 (74.240)
(74.240)
Faisons quand même le développement détaillé pour
un système parallèle à deux composantes dont le taux de
défaillance est constant et non identique. Pour cela, nous partons
de la relation démontrée plus haut:
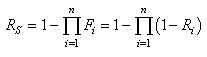 (74.241)
(74.241)
Soit dans le cas où n vaut 2, nous avons:
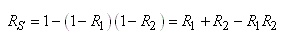 (74.242)
(74.242)
et donc:
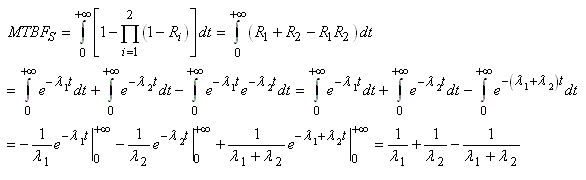 (74.243)
(74.243)
Donc si 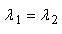 ,
nous avons: ,
nous avons:
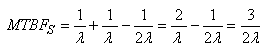 (74.244) (74.244)
Soit:
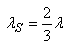 (74.245)
(74.245)
Avant de continuer avec d'autres topologies, voici un exemple
d'un petit devoir scolaire (avec solution) mélangeant topologie parallèle
et et série qui montre que cela ne s'applique pas seulement à des machines.
Exemple:
Un laborantin doit quotidiennement effectuer 3 tests différents
sur un échantillon, donné : Les tests A , B et C dans l'ordre
donné! Nous savons que les laborantins ratent le test A une
fois sur quatre mais peuvent le recommencer 2 fois en cas d'échec
(donc ils peuvent le faire 3 fois au total), ils réussissent le
B dans 96% des cas et peuvent aussi le recommencer une fois en cas d'échec
(donc ils peuvent le faire 2 fois au total), il ratent le test C une
fois sur deux et ne peuvent pas le recommencer. Quelle est la probabilité qu'un
laborantin réussisse les 3 tests de suite?
Pour résoudre cet exercice il faut voir chacun des tests
reproducible comme un processus parallèle et l'ensemble des tests comme
un processus série. Nous avons alors la probabilité totale qui est:
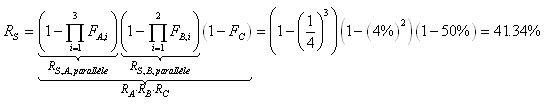 (74.246)
(74.246)
T3. Topologie k/n:
Ce système fonctionne si k parmi n composants de même
loi de fiabilité R fonctionnent. C'est typiquement le cas des
disques RAID en informatique pour lesquels il en faut plus d'un qui fonctionne
toujours à la
fin et ce nombre est déterminé par le volume de données.
Il s'agit aussi principe de fonctionnement des système de vote à redondance
dans les avions où nous avons un système 2/3 appelé "triplex".
Nous avons alors la représentation schématique suivante:

Figure: 74.20 - Topologie k/n
Dans le cadre des arbres de défaillance probabilistes (cf.
chapitre Techniques De Gestion), cette topologie correspond à une
porte k-OU (Voting OR) avec n entrées car il faut
au moins que k blocs soient en panne pour que la sortie ne fonctionne
plus:
Figure: 74.21 - Porte k-OU (Voting OR)
Donc chercher la loi de probabilité cumulée de fiabilité revient à se
poser la question de la probabilité cumulée d'avoir k éléments
qui fonctionnent parmi n qui sont non distinguables.
Cela revient donc à utiliser la loi binomiale (cf.
chapitre de Statistiques) pour laquelle nous avons démontré que la
probabilité cumulée était donnée alors par:
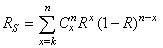 (74.247)
(74.247)
Cette relation ext extrêmement importante dans la pratique
de l'ingénerie de la fiabilité!!! Nous remarquons ainsi que
pour k égalant n nous retrouvons la fiabilité d'un
système
série dont les éléments ont tous la même fiabilitié:
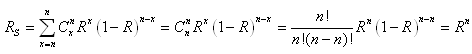 (74.248)
(74.248)
Et pour k égalant 1, nous retrouvons la fabilité
d'un système parallèle dont les éléments ont
tous la même
fiabilitié (revoir les propriétés du coefficient bionomial
dans le chapitre de Calcul Algébrique si nécessaire):
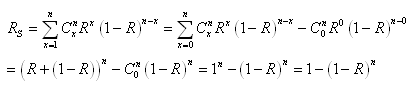 (74.249)
(74.249)
Dans le cas du triplex, nous avons donc:
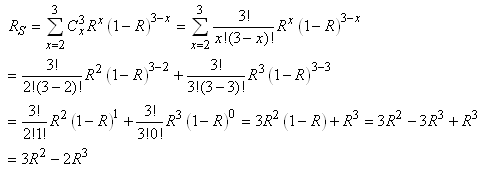 (74.250)
(74.250)
Par exemple, si la fiabilité est donnée par une loi exponentielle
où nous avons déjà démontré que:
(74.251)
Nous avons alors:
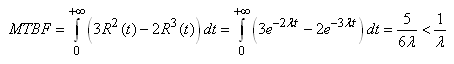 (74.252)
(74.252)
Donc la MTBF globale du système 2/3 est plus grande qu'un système simple ce
qui évidemment est le but recherché.
T4. Topologie série/parallèle et parallèle/série à configuration symétrique:
Ce sont simplement des compositions simples des deux premiers systèmes étudiées
précédemment.
Nous avons d'abord le système série/parallèle:

Figure: 74.22 - Topologie série/parallèle symétrique
Or, comme les systèmes séries sont donnés par:
(74.253)
et les parallèles par:
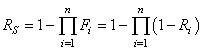 (74.254)
(74.254)
la composition des deux donne trivialement dans notre cas ci-dessus:
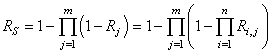 (74.255)
(74.255)
Et nous avons dans la famille aussi le système parallèle/série:

Figure: 74.23 - Topologie parallèle/série symétrique
où en utilisant exactement la même démarche que précédemment nous avons:
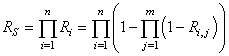 (74.256)
(74.256)
T5. Topologie complexe:
Au fait, il ne s'agit pas vraiment de systèmes complexes mais ils nécessitent
simplement une petite maîtrise des axiomes de probabilités. L'exemple particulier
qui va nous intéresser est le suivant (typiquement filtre RLC en cascade):

Figure: 74.24 - Topologie complexe
dénommé "réseau avec bridge".
Et nous devinons que ce qui rend le système complexe est le composant 5.
Nous pouvons alors considérer une première approche qui est de décomposer le
problème.
Le système par rapport au composant 5 sera soit dans l'état:

Figure: 74.25 - Décomposition du système (première étape)
s'il est défectueux avec une loi de densité probabilité:
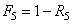 (74.257)
(74.257)
et ayant lui-même une fiabilité de:
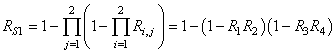 (74.258)
(74.258)
selon nos résultats précédents du système complexe série/parallèle.
Soit dans l'état suivant s'il est fonctionnel avec une loi de densité probabilité 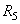 : :
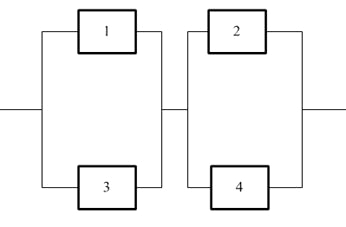
Figure: 74.26 - Décomposition du système (deuxième et dernière étape)
et ayant lui-même une fiabilité de:
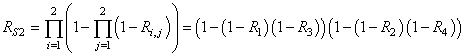 (74.259)
(74.259)
selon nos résultats précédents du système complexe parallèle/série.
Comme le système ne peut pas être dans les deux états en même temps, nous
avons affaire à une probabilité disjointe (cf. chapitre
de Probabilités) soit la somme des densités auxquelles nous devons associer
les autres composants. Dès lors nous avons:
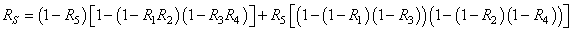 (74.260)
(74.260)
Nous pouvons alors à l'aide de l'ensemble des 5 topologies précédentes faire
une évaluation de la fiabilité d'un système quelconque!
Une autre stratégie pour les systèmes complexes consiste
à les décomposer en système séries
ou parallèles simples. Si cela n'est pas possible, nous pouvons calculer
la fiabilité de chaque configuration du système qui est considérée
comme fonctionnant et faire ensuite la somme des probabilités de fonctionnement
de chaque configuration.
Faisons un exemple en considérant le cas particulier suivant:

Figure: 74.27 - Cas particulier de système supposé comme complexe
Et considérons la table de vérité suivante avec les 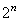 configurations
possibles: configurations
possibles:
État n° |
Bloc 1 |
Bloc 2 |
Bloc 3 |
Sortie |
1 |
0 |
0 |
0 |
0 |
2 |
1 |
0 |
0 |
0 |
3 |
0 |
1 |
0 |
0 |
4 |
1 |
0 |
1 |
1 |
5 |
0 |
1 |
1 |
1 |
6 |
1 |
1 |
1 |
1 |
7 |
1 |
1 |
0 |
0 |
8 |
0 |
0 |
1 |
0 |
Tableau: 74.9 - Table de vérité d'un système de maintenance préventive
Le principe (il faut le savoir...) consiste à dire qu'un état UP (valant
donc: 1) est affecté à la valeur 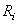 du
bloc i concerné et que l'état DOWN (valant donc: 0) est affecté à la
valeur du
bloc i concerné et que l'état DOWN (valant donc: 0) est affecté à la
valeur 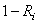 du
bloc i. Chaque valeur sera multipliée avec les autres pour obtenir la
fiabilité totale du système à un état donné. du
bloc i. Chaque valeur sera multipliée avec les autres pour obtenir la
fiabilité totale du système à un état donné.
Ainsi, dans l'exemple précédent, nous avons donc que 3 états qui permettent
au système de fonctionner. Calculons leur fiabilité respective. Les états n°4
et n°5 donnent donc par définition:
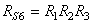 (74.261)
(74.261)
L'état n°6 donne lui par définition:
(74.262)
et nous sommons le tout comme indiqué ultérieurement:
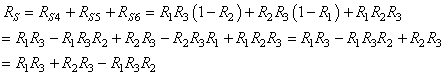 (74.263)
(74.263)
Et nous pouvons vérifier que cette approche est effectivement correcte en
prenant la relation générale d'un tel système démontrée plus haut:
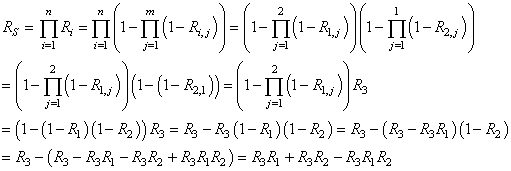 (74.264)
(74.264)
ce qui montre que nous avons bien le même résultat et que l'approche par
décomposition fonctionne aussi.
Enfin, signalons pour terminer que lorsque nous incluons dans les systèmes
des éléments qui permettent de tolérer ou d'accepter certaines
erreurs, nous parlons alors de "tolérance
aux fautes" et
nous en distinguons principalement de trois types:
- Redondance active: Dans ce cas tous les composants redondants fonctionnent
en même temps.
- Redondance passive: Un seul élément redondant fonctionne,
les autres sont en attente, ce qui a pour avantage de diminuer ou de supprimer
le vieillissement
des éléments redondants, mais en contrepartie nécessite
l'insertion d'un composant de détection de panne et de commutation.
- Redondance majoritaire: Cette redondance concerne surtout des signaux.
Le signal de sorite sera celui de la majorité des composants redondants.
ARBRES DE DÉFAILLANCES PROBABILISTES
Un arbre de défaillances (aussi appelée arbre de pannes
ou arbre de fautes) ou "fault tree analysis" en anglais est une technique
d'ingénierie
très
utilisée dans les études de sécurité et de
fiabilité des systèmes consistant à représenter
graphiquement les combinaisons possibles d’événements
qui permettent la réalisation d’un événement
indésirable prédéfini. Une telle représentation
graphique met donc en évidence les relations de cause à effet.
Cette technique est complétée par un traitement mathématique
qui permet la combinaison de défaillances simples ainsi que de leur
probabilité d'apparition. Elle permet ainsi de quantifier la probabilité d'occurrence
d'un événement indésirable.
Le principe est très simple tant que l'on fait appel à des
probabilités
binaires, par contre dès qu'il faut utiliser des fonctions de distributions
continues (cas le plus fréquent dans la pratique), il faut passer
par des simulations de Monte-Carlo (cf. chapitre
de Méthodes Numériques)
avec typiquement des logiciels comme Weibull++.
Considérons l'arbre de défaillance ci-dessous qui comporte donc 5 événements
primitifs et 3 événements combinés avec les probabilités des événtements
primites supposés connus:

Figure: 74.28 - Arbre de défaillance simple à probabilités binaires et portes ET/OU seules
Nous avons alors pour l'événement E6 la probabilité suivante puisqu'il
s'agit d'une porte ET (assimilable à un système parallèle):
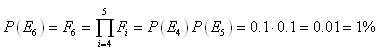 (74.265)
(74.265)
et pour l'événement E7 puisqu'il s'agit d'une porte OU (assimilable
à un système série), nous avons.
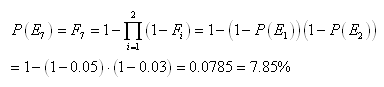 (74.266)
(74.266)
Et donc au final:
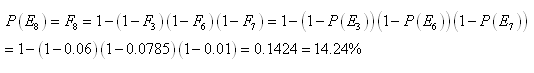 (74.267)
(74.267)
Ainsi, la probabilité d'avoir la chambre de travail sans
lumière est de 14.24%.
MÉTHODE DU MAXIMUM DE VRAISEMBLANCE
Nous avons étudié dans le chapitre de Statistiques que l'utilisation de la
technique du maximum de vraisemblance permettait d'estimer la valeur maximale
ou minimale des paramètres d'une loi statistiques sous les hypothèses d'indépendance
des événements.
Cette technique,bien qu'empirique et tout à fait discutable, peut être
utilisée
dans le domaine de la fiabilité. Comme la théorie a déjà été développée
dans le chapitre de Statistiques, voyons de suite des cas pratiques.
Exemples:
E1. Considérons un système dont les intervalles de temps
entre deux pannes est distribué selon un loi exponentielle:
(74.268)
de paramètre 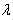 inconnu
et où nous considérerons (comme toujours...) que chaque panne
est indépendante.
Des observations nous ont
donné le nombre
de mois suivants entre chaque panne: 10, 5, 11, 12, 15. inconnu
et où nous considérerons (comme toujours...) que chaque panne
est indépendante.
Des observations nous ont
donné le nombre
de mois suivants entre chaque panne: 10, 5, 11, 12, 15.
En utilisant alors le maximum de vraisemblance qui consiste donc à maximiser
la propabilité totale d'événements indépendants (donc il faut multiplier),
nous avons:
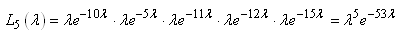 (74.269)
(74.269)
Donc déterminer le taux de défaillance qui maiximise la vraisemblance
consiste à calculer quand la dérivée s'annule:
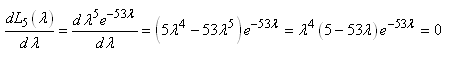 (74.270)
(74.270)
Nous avons alors deux racines triviales qui sont:
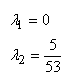 (74.271)
(74.271)
et évidemment nous allons conserver la deuxième racine comme
taux de défaillance de notre système.
E2. Nous considérons les mêmes données
qu'avant mais avec cette fois-ci une loi de Weibull avec la notation simplifiée
suivante:
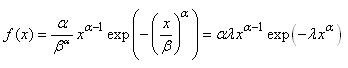 (74.272)
(74.272)
et donc:
 (74.273)
(74.273)
Pour cherche à maximiser ce genre de fonction formellement
il n'existe pas de méthodes connue (du moins à ma connaissance...). Par
contre, un tableur comme MS Excel avec son solveur permet de trouver les
deux paramètres de cette loi de Weibull en trois clics!
E3. Nous supposons que nous mettons sous observation 10 éléments
de fabrication identique. Parmi les 10, nous avons observé un
arrêt
de 4 d'entre eux après 700, 800, 900 et 950 heures. Les 6 éléments
restants seront considérés comme dépassant les 1'000
heures mains nous arrêtons l'observation
à partir de cette valeur. En supposant que la loi de défaillance
est à nouveau exponentielle, nous avons alors (l'idée
est subtile mais simple):
 (74.274)
(74.274)
Il vient alors:
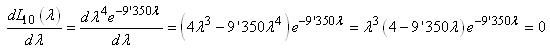 (74.275)
(74.275)
Nous avons alors deux racines triviales qui sont:
 (74.276)
(74.276)
et évidemment nous allons conserver la deuxième
racine comme taux de défaillance de notre système. MODÈLE DE SURVIE DE KAPLAN-MEIER
Dans des domaines comme l'industrie, la médecine ou en biologie, nous intéressons
souvent aux:
- Durée de survie après un événement grave
- Durée de rémission après un traitement ou une opération
- Durée d'un symptôme après une anomalie
- Durée d'une infection sans symptôme
Nous cherchons très souvent à distinguer au moins "l'événement
d'intérêt":
- Arrêt du système après l'événement grave
- Fin de la rémission
- Fin d'un symptôme après anomalie
- Début d'un symptôme lors d'une infection
de la variable a expliquer "durée avant l'apparition
de l'événement d'intérêt":
- Temps écoulé avant l'arrêt du système
- Temps écoulé avant la fin de la rémission
- Temps écoulé avant la fin du symptôme
- Temps écoulé sans symptôme
Définitions:
D1. Nous appelons "rémission",
la diminution d'une maladie ou d'un dysfonctionnement de façon temporaire.
D2. La "durée de survie" ou "durée
de vie" T désigne le temps qui s'écoule depuis un instant
initial (début d'un traitement, diagnostic, panne, etc.) jusqu'à la survenue
d'un événement d'intérêt final (décès du patient, rechute, rémission, guérison,
réparation, etc.). Nous disons que l'objet de l'étude "survit au temps t" si, à cet
instant l'évènement d'intérêt final n'a pas encore eu lieu.
Remarque: Bien que ce type d'étude puisse être associé à la maintenance préventive,
les statisticiens l'associent plutôt au domaine de "l'analyse
de la survie".
Nous nous intéresserons dans le cas présent à un cadre particulier mais qui
peut être facilement généralisé:
- Cohorte/Essai clinique où nous étudions la durée de survie de chaque patient
(machine).
- Tous les patients (machines) n'ont pas la même durée d'observation (instants
différents d'entrée dans l'étude).
- Nous avons des informations sur le temps de survie de chaque patient (machine)
mais nous ne savons pas quand il arrive exactement.
Des deux derniers points, nous concluons que le temps de survie peut être
censuré. Donc les techniques statistiques habituelles ne s'appliquent pas directement
car les données censurées demandent un traitement particulier (bien évidemment,
nous enlevons les données censurées nous perdons de l'information). Il va sans
dire que ce type de situation est extrêmement fréquent et donc l'étude de l'estimation
de Kaplan-Meier est très importante.
Définition: La durée T est dite censurée si la durée n'est pas intégralement
observée. Les différents types de censures sont:
- La censure de type I: fixée à droite. Dans cette situation, la durée n'est
pas observable au-delà d'une durée maximale, fixe appelée "censure
fixe" et imposée. Donc, soit nous avons l'opportunité d'observer
la vraie durée de l'événement d'intérêt pour l'élément s'il a lieu avant la
censure fixe, soit nous nous contenterons de la durée de la censure fixe s'il
l'événement d'intérêt n'a pas eu lieu avant.
- La censure de type I: fixée à gauche. Dans cette situation, la durée d'étude
n'est pas observable avant une date connue appelée "censure
d'attente" et imposée. Donc soit, l'événement d'intérêt a lieu
au moment de la censure d'attente, soit après. S'il y a lieu après, nous considérerons
la durée entre la date de la censure et la date de l'événement d'intérêt.
- La censure de type II: attente. Dans cette situation, nous observons les
durées de vie de n individus jusqu'à ce que m individus aient
vu l'évènement se produire (décédés). La durée considérée est donc celle du
début de l'expérience jusqu'à l'événement d'intérêt pour le m-ème.
- La censure de type III: aléatoire à gauche. Dans cette situation, nous
ne connaissons pas quand l'événement d'intérêt a eu lieu (car nous avons commencé à observer
le sujet d'étude trop tard). Nous ne pouvons alors pas traiter des "durées" dans
le sens mesurable du terme et il nous faudra nous limite à un simple comptage.
- La censure de type III: aléatoire à droite. Dans cette situation, nous
ne connaissons pas quand l'événement aura lieu (car nous avons arrêté d'observer
le sujet avant qu'il y ait lieu pour une raison quelconque). Nous ne pouvons
alors pas traiter des "durées" dans le sens mesurable du terme et
il nous faudra nous limite à un simple comptage.
- La censure de type IV: aléatoire par intervalle. Dans cette situation,
nous avons un mélange de la censure aléatoire à gauche et à droite. C'est-à-dire
que pour certains sujets d'étude, nous ne savons pas quand l'événement d'intérêt
a commencé, et pour d'autres, nous ne savons pas quand il aura lieu (s'il a
lieu....).
Dans l'industrie des machines, nous savons souvent affaire à la censure de
type I: fixée droite. Dans le domaine médical, lors d'essais cliniques,
nous avons souvent affaire à une censure aléatoire à droite. Dans le cas des
pandémies, nous avons affaire à des censure de type aléatoire à gauche.
Supposons que l'étude soit un essai clinique portant sur deux groupes de
patients recevant deux types de traitements. Deux questions importantes se
posent aux médecins:
Q1. L'un des deux traitements est-il plus efficace que l'autre en matière
d'amélioration de la survie des patients?
Q2. Peut-on mettre en évidence des facteurs prognostiques, c'est-à-dire qui
améliorent/détériorent la survie?
Pour répondre à la question Q1 nous pouvons mettre en place des méthodes
statistiques qui vont permettre de comparer les deux groupes de patients qui
reçoivent les deux types de traitement.
Pour répondre à la question Q2 nous pouvons proposer un modèle qui relie
la durée de survie des patients à des variables explicatives et mettre en évidence
des facteurs pronostiques.
Accompagnons la théorie directement d'un exemple et considérons le tableau
suivant où deux cohortes de patients (nous passons de l'ingénierie
mécanique à l'ingénierie
humaine...) de même taille
initiale atteints de leucémie aiguë testent un médicament (6-MP) contre un
placebo de façon bien évidemment aveugle.
Nous avons les durées de rémission suivantes pour 21 patients (le tableau
de 21 lignes indique donc le nombre de semaines pendant lesquelles un patient
est considéré comme
guéri après traitement avant de rechuter):
|
6-mercaptopurine (6-MP)
|
Placebo
|
|
6
|
1
|
|
6
|
1
|
|
6
|
2
|
|
6+
|
2
|
|
7
|
3
|
|
9+
|
4
|
|
10
|
4
|
|
10+
|
5
|
|
11+
|
5
|
|
13
|
8
|
|
16
|
8
|
|
17+
|
8
|
|
19+
|
8
|
|
20+
|
11
|
|
22
|
11
|
|
23
|
12
|
|
25
|
12
|
|
32+
|
15
|
|
32+
|
17
|
|
34+
|
22
|
|
35+
|
23
|
Tableau: 74.10 - Analyse de survie de deux cohortes avec censure à droite
Le signe + correspond à des patients qui ont quitté l'étude à la semaine
considérée. Ils sont donc censurés. Par exemple, le 4ème patient est perdu
de vue pour une raison quelconque au bout de 6 semaines de traitement avec
le 6-MP: il a donc une durée de rémission supérieure à 6 semaines. Donc dans
l'étude 6-MP, il y a 21 patients avec et 12 données censurées.
Remarque: Le modèle théorique suppose que la censure est indépendant du
temps de survie (censure non informative). Mais si la censure est du à l'arrêt
du traitement, l'hypothèse d'indépendance n'est pas valide.
Pour le groupe placebo il est simple de faire une courbe de survie. Il suffit
de produire le tableau suivant (pour les semaines omises, on impose bien évidemment
le nombre de rémission comme constantes):
|
Semaine i
|
Nombre de rémission
à la semaine i
|
Proportion (probabilité)
de rémission à la semaine i
|
|
0
|
21
|
100%
|
|
1
|
19
|
19/21=90%
|
|
2
|
17
|
17/21=81%
|
|
3
|
16
|
16/21=76%
|
|
4
|
14
|
14/21=67%
|
|
5
|
12
|
12/21=57%
|
|
8
|
8
|
8/21=38%
|
|
11
|
6
|
6/21=29%
|
|
12
|
4
|
4/21=19%
|
|
15
|
3
|
3/21=14%
|
|
17
|
2
|
2/21=10%
|
|
22
|
1
|
1/20=0.05%
|
|
23
|
0
|
0
|
Donc si les données ne sont pas censurées, la survie  peut être
estimée par la proportion d'individus ayant survécu à l'instant t,
qu'il est d'usage d'écrire sous la forme mathématique suivante: peut être
estimée par la proportion d'individus ayant survécu à l'instant t,
qu'il est d'usage d'écrire sous la forme mathématique suivante:
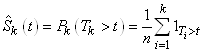 (74.277)
(74.277)
L'idée est donc d'estimer:
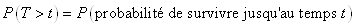 (74.278)
(74.278)
par la la proportion de patients ayant survécu jusqu'au temps t.
Si les données sont censurées, l'estimation de la fonction de survie nécessite
des outils spécifiques. Kaplan et Meier ont proposé dans ce cas particulier
le calcul suivant:

(74.279)
Voyons cela sous une forme un peu plus mathématique. Si nous notons 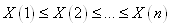 les
instants (ordonnées) où un évènement s'est produit (décès ou censure), nous
avons alors: les
instants (ordonnées) où un évènement s'est produit (décès ou censure), nous
avons alors:
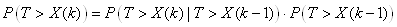 (74.280)
(74.280)
Avec bien évidemment:
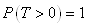 (74.281)
(74.281)
Nous estimons:
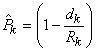 (74.282)
(74.282)
où 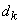 est
le nombre de décès observé au temps correspondant à l'événement est
le nombre de décès observé au temps correspondant à l'événement 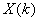 et et 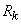 est
le nombre d'individus à risque (exposés au risque de décès) juste avant . est
le nombre d'individus à risque (exposés au risque de décès) juste avant .
Nous définissons l'estimateur de Kaplan-Meier pour tout 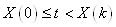 : :

|
Durée de rémission
(non censurées) observées
|
Sujets en rémission au début de k
|
Probabilité de ne pas rechuter à k sachant qu'on est en
rémission à k-1
|
Probabilité de survie de
Kaplan-Meier
|
|
0
|
21
|
21/21=100%
|
100%
|
|
6
|
21
|
18/21=85.7%
|
100%*85.7%=85.7%
|
|
7
|
17
|
16/17=94.1%
|
85.7%*94.1%=80.7%
|
|
10
|
15
|
14/15=93.3%
|
80.7%*93.3%=75.3%
|
|
13
|
12
|
11/12=91.7%
|
75.3%*91.7%=69%
|
|
16
|
11
|
10/11=90.9%
|
69%*90.9%=62.7%
|
|
22
|
7
|
6/7=85.7%
|
62.7%*85.7%=53.8%
|
|
23
|
6
|
5/6=83.3%
|
53.8%*83.3%=44.8%
|
Nous retrouvons donc les mêmes valeurs que celles données
par exemple par le logiciel de statistiques Minitab 15.1.1.
MÉTHODE ABC
Dans une entreprise, les tâches sont nombreuses et les équipes
d'entretien et de maintenance sont systématiquement réduites à leur
minimum par les temps qui courent. De plus, les technologies les plus évoluées en matière de maintenance coûtent
cher ou peuvent coûter très cher, et ne doivent pas être appliquées
sans discernement.
Il convient par conséquent de s'organiser de façon efficace
et rationnelle. L'analyse ABC (on devrait dire en toute rigueur "objectif ABC"),
utilisant implicitement la loi de probabilité cumulée
de Pareto (cf. chapitre de Statistiques), permet
d'y remédier
relativement bien. Ainsi, un classement des coûts par rapport aux types de
panne donne des priorités sur les interventions à mener (cette
méthode
empirique est aussi utilisée dans de nombreux autres domaines dont un
qui est très connu: la gestion de stocks).
L'idée consiste dans un premier temps comme pour l'analyse de Pareto (cf.
chapitre de Techniques de Gestion) de classer les pannes par ordre
croissant de coût de maintenance (ou de coût d'impact en cas de panne) chaque
panne se rapportant un système simple ou complexe et à établir un graphique
faisant correspondre les pourcentages de coûts cumulées aux pourcentages
de type de panne cumulés.
Ensuite, nous distinguons par tradition dans l'industrie trois zones:
- Zone A: Dans la majorité des cas, environ 20% des pannes représentent 80%
des coûts et il s'agit donc de la zone prioritaire.
- Zone B: Dans cette tranche, les 30% de pannes suivantes coûtent 15% supplémentaires.
- Zone C: 50% des pannes restantes ne revient qu'à 5% des coûts.
Le domaine du web participatif considère lui des zones (objectifs)
de respectivement 90-9-1 pourcents donc on trouve vraiemnt de tout et n'importe
quoi...
Voyons un exemple en considérant que les données suivantes ont été recueillies
et que nous aimerions faire une analyse du % de machines sur lesquelles il
faudrait que nous nous concentrions pour diminuer le coût d'heures de pannes
d'environ 80% (dans la réalité on s'intéressera plus au % du coût
financier!).
N° de Machine |
Heures d'arrêt |
Nb. de pannes |
Machine n°1 |
100 |
4 |
Machine n°2 |
32 |
15 |
Machine n°3 |
50 |
4 |
Machine n°4 |
19 |
14 |
Machine n°5 |
4 |
3 |
Machine n°6 |
30 |
8 |
Machine n°7 |
40 |
12 |
Machine n°8 |
80 |
2 |
Machine n°9 |
55 |
3 |
Machine n°10 |
150 |
5 |
Machine n°11 |
160 |
4 |
Machine n°12 |
5 |
3 |
Machine n°13 |
10 |
8 |
Machine n°14 |
20 |
8 |
Tableau: 74.11
- Analyse ABC sur pannes machines
Ensuite, dans un tableur comme Microsoft Excel ou autre... nous pouvons
aisément établir
le tableau suivant:
Machine |
Arrêt [h.] |
Cumul [h.] |
%Cumulé |
Pannes |
Cumul pannes |
%Cumulé |
11 |
160 |
160 |
21.19% |
4 |
4 |
4.30% |
10 |
150 |
310 |
41.06% |
5 |
9 |
9.68% |
1 |
100 |
410 |
54.30% |
4 |
13 |
13.98% |
8 |
80 |
490 |
64.90% |
2 |
15 |
16.13% |
9 |
55 |
545 |
72.19% |
3 |
18 |
19.35% |
3 |
50 |
595 |
78.81% |
4 |
22 |
23.66% |
7 |
40 |
635 |
84.11% |
12 |
34 |
36.56% |
2 |
32 |
667 |
88.34% |
15 |
49 |
52.69% |
6 |
30 |
697 |
92.32% |
8 |
57 |
61.29% |
14 |
20 |
717 |
94.97% |
8 |
65 |
69.89% |
4 |
19 |
736 |
97.48% |
14 |
79 |
84.95% |
13 |
10 |
746 |
98.81% |
8 |
87 |
93.55% |
12 |
5 |
751 |
99.47% |
3 |
90 |
96.77% |
5 |
4 |
755 |
100.00% |
3 |
93 |
100.00% |
Tableau: 74.12
- Normalisation des données pour analyse ABC
Nous avons alors graphiquement:

Figure: 74.29 - Graphique de la méthode ABC
où les zones A, B et C sont arrondies à des points existants.
Ainsi, la zone critique A compte les machines 11, 10, 1, 8, 9 et 3.
Une amélioration de la fiabilité de ces machines peut donc procurer
jusqu'à 78.8%
de gain de temps sur les pannes.
Maintenant déterminons les paramètres de la loi de répartition de Pareto:
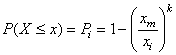 (74.283) (74.283)
Nous devons déterminer 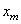 et k les
autres paramètres nous sont donnés par nos mesures (le tableau). et k les
autres paramètres nous sont donnés par nos mesures (le tableau).
Nous pouvons jouer de la manière suivante:
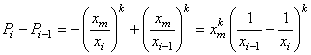 (74.284) (74.284)
d'où:
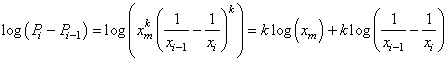 (74.285) (74.285)
Donc à l'aide de:
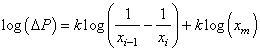 (74.286)
(74.286)
on doit pouvoir déterminer les deux paramètres recherchés en considérant
l'expression comme l'équation d'une droite dont k est la pente et 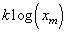 l'ordonnée à l'origine: l'ordonnée à l'origine:
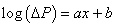 (74.287) (74.287)
Une régression linéaire simple (cf. chapitre de Méthodes
Numériques) nous donne:
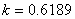 et et 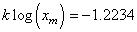 (74.288)
(74.288)
donc:
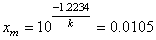 (74.289) (74.289)
Nous avons donc au final:
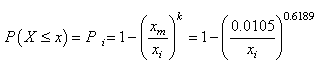 (74.290)
(74.290)
Ce qui donne alors le tableau suivant (les xi de la loi de Pareto sont les
%Cumulé de panne):
Machine |
%Cumulé coûts [h.] |
%Cumulé panne |
%Cumulé loi Pareto |
11 |
21.19% |
4.30% |
61.76% |
10 |
41.06% |
9.68% |
78.01% |
1 |
54.30% |
13.98% |
82.89% |
8 |
64.90% |
16.13% |
84.48% |
9 |
72.19% |
19.35% |
86.29% |
3 |
78.81% |
23.66% |
88.05% |
7 |
84.11% |
36.56% |
91.12% |
2 |
88.34% |
52.69% |
93.08% |
6 |
92.32% |
61.29% |
93.75% |
14 |
94.97% |
69.89% |
94.29% |
4 |
97.48% |
84.95% |
95% |
13 |
98.81% |
93.55% |
95.32% |
12 |
99.47% |
96.77% |
95.43% |
5 |
100.00% |
100.00% |
95.53% |
Tableau: 74.13
- Comparaisons données expérimentales/théoriques
Nous pouvons alors obtenir la vraie courbe de Pareto correspondante facilement
dans Microsoft Excel 11.8346:

Figure: 74.30 - Graphique de la méthode ABC associé à une courbe de Pareto
La différence entre la courbe expérimentale est la théorique
est non négligeable... Comme k est inférieur à 1, alors
comme nous l'avons vu démontré dans le chapitre de Statistiques,
la loi de Pareto n'a ni espérance,
ni variance.
Il faut faire attention au fait que dans le domaine de la gestion, la
loi de Pareto est utilisée un peu à tort et à travers
alors qu'une autre loi de probabilité pourrait être beaucoup plus
adaptée.
Par ailleurs, un simple test d'ajustement du Khi-deux (cf.
chapitre de Statistiques) nous montre qu'il faut rejeter l'approximation
par une loi de Pareto. Par ailleurs, des logiciels spécialisés
comme @Risk rejettent l'approximation par Pareto au-delà des 20 meilleurs
ajustements, le meilleur ajustement étant selon ce même logiciel une
loi log-normale.
PLANS D'EXPÉRIENCE
Le comportement ou l'appréciation subjective de produits industriels
ou manufacturées est généralement
fonction de nombreux phénomènes, souvent dépendants
les uns des autres. Pour prévoir ce comportement/appréciation, le
produit et les phénomènes
sont modélisés, et des simulations sont effectuées.
La pertinence des résultats des simulations dépend évidemment
de la qualité des
modèles.
En particulier, dans le cadre de la conception ou reconception d'un produit,
les modèles font généralement intervenir un certain nombre
de grandeurs physiques (paramètres) que l'on s'autorise à modifier.
Le comportement des produits industriels est généralement
fonction de nombreux phénomènes, souvent dépendants les
uns des autres. Pour prévoir ce comportement, le produit et les phénomènes
sont modélisés, et des simulations sont effectuées.
Or, ces essais sont coûteux, et ce d'autant plus que le nombre de paramètres à faire
varier est important. En effet, la modification d'un paramètre peut
par exemple exiger un démontage et un remontage du produit, ou bien
la fabrication de plusieurs prototypes différents (cas d'une pièce
produite en série), ou encore l'interruption de la production pour changer
d'outil (cas d'un processus de fabrication)... Le coût d'une étude
expérimentale dépend donc du nombre et de l'ordre des essais
effectués.
L'idée consiste alors à sélectionner et
ordonner les essais afin d'identifier, à moindres coûts, les effets
des paramètres sur la réponse du produit. Il s'agit de méthodes
statistiques faisant appel à des notions mathématiques simples
le plus souvent. La mise en oeuvre de ces méthodes comporte trois étapes
(mais mieux vaut se référer à la norme ISO 3534-3:1999
sur le sujet pour être plus rigoureux!):
1. Postuler un modèle de comportement du système (avec des
coefficients pouvant être inconnus)
2. Définir un protocole d'expérience,
c'est-à-dire une série
d'essais ("runs" en anglais) permettant d'identifier les coefficients du
modèle
3. Faire
les essais, identifier les coefficients ("constrasts" en
anglais) et variables influentes
4. Déterminer les valeurs des variables qui permettent d'arriver au plus
proche d'un résultat désiré ou ayant une variabilité minimale et conclure.
Les plans d'expériences ("Design of Experiment" (D.O.E.)
en anglais abrégés PEX en français) permettent d'organiser
au mieux les essais qui accompagnent une recherche
scientifique ou des études industrielles. Ils sont applicables à de
nombreuses disciplines et à toutes les industries à partir du moment où l'on
recherche le lien qui existe entre une grandeur d'intérêt, y (quantité de
rebus, défauts, détections, amplitude, etc.), et des variables  dans
un but d'optimisation. Raison pour laquelle il existe des logiciels
pour les traiter comme Minitab ou principalement JMP pour ne citer que les
plus connus. dans
un but d'optimisation. Raison pour laquelle il existe des logiciels
pour les traiter comme Minitab ou principalement JMP pour ne citer que les
plus connus.
Indiquons également que les plans d'expérience sont un des
piliers de la chimiométrie
(outils mathématiques, en particulier statistiques, pour obtenir
le maximum d'informations à partir des données chimiques).
Au cours des dernières années du 20ème siècle,
l'application des plans d'expérience
s'est développée, particulièrement en raison du fait
reconnu que ceux-ci sont essentiels pour l'amélioration de la qualité des
biens et des services. Bien que la maîtrise statistique de la qualité,
les solutions managériales,
les inspections, et autres outils de qualité remplissent également
cette fonction, le plan d'expérience représente la méthodologie
par excellence dans le cas d'un environnement de paramètres complexes,
variables et interactifs. D'un point de vue historique, les plans d'expérience
ont évolué et se sont développés
dans le secteur de l'agriculture. La médecine a également bénéficié d'une
longue histoire de plans d'expérience élaborés avec
soin. Actuellement, les environnements industriels témoignent de bénéfices
considérables de la méthodologie,
en raison de la facilité d'initiation des efforts (logiciels d'application conviviaux), d'une meilleure formation, de défenseurs
influents, et des nombreux succès obtenus grâce aux plans d'expérience.
Il existe trois grandes familles de plans d'expériences:
1. Les "plans de criblages": dont l'objectif
est de découvrir
les facteurs les plus influents sur une réponse donnée en un
minimum d'expériences. C'est la plus simple des familles car proche
de l'intuition expérimentale (elle est parfois considérée
comme une sous-famille de la deuxième famille car elle fait abstraction
des interactions des facteurs et se réduit donc à un modèle purement additif).
2. Les "plans de modélisation":
dont l'objectif est de trouver la relation mathématique qui lie les
réponses mesurées
aux variables associées aux facteurs soit via une démarche mathématique
analytique ou purement matricielle. Les plans factoriels complets et fractionnaires
(2 niveaux par facteurs avec modèles linéaires) ainsi que les
plans pour surfaces de réponse (au moins 3 niveaux par facteurs avec
modèles du second degré) font partie de cette famille.
3. Les "plans de mélange": dont
l'objectif est le même
que la deuxième famille, mais où les facteurs ne sont pas indépendants
et sont contraints (par exemple leur somme ou leur rapport doit être égale à une
certaine constante).
La technique des plans d'expérience a pour objectif d'être
scientifiquement plus avantageuse que les techniques consistantes à changer
seulement un facteur
à
la fois (en laissant donc fixes les autres facteurs) car cette dernière
ne permet pas de faire faire une étude statistiques approfondie
des erreurs et (surtout!) masque complétement les interactions.
Le principe général de la stratégie des plans d'expérience se base sur le
fait que l'étude
d'un phénomène
peut, le plus souvent, être schématisé de la manière suivante:
nous nous intéressons à une
grandeur, y qui dépend d'un grand nombre de variables, 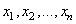 (et
leur ordre n'a pas d'influence... ce qui est par contre problématique
en chimie...). (et
leur ordre n'a pas d'influence... ce qui est par contre problématique
en chimie...).
La modélisation mathématique consiste à trouver une fonction f telle
que:
 (74.291)
(74.291)
qui prenne en compte l'influence de chaque facteur seul ou des facteurs
combinés
(interactions).
Une méthode classique d'étude consiste en la mesure de la réponse y pour
plusieurs valeurs de la variable tout
en laissant fixe la valeur des (n-1) autres variables. Nous itérons
alors cette méthode pour chacune des variables.
Ainsi, par exemple, si nous avons 8 variables et si l'on décide de donner
2 valeurs expérimentales à chacune d'elles, nous sommes conduits à effectuer  expériences. expériences.
Ce nombre élevé dépasse les limites de faisabilité tant en temps qu'en coût.
Il faut donc réduire le nombre d'expériences à effectuer sans pour autant perdre
sur la qualité des résultats recherchés.
L'utilisation d'un plan d'expérience donne alors une stratégie dans le choix
des méthodes d'expérimentation. Le succès des plans d'expériences dans la recherche
et l'industrie est lié au besoin de compétitivité des entreprises: ils permettent
une amélioration de la qualité et une réduction des coûts.
Remarque: La méthode des plans d'expériences a été mise au point au début
du siècle, dans les années 1920, par Ronald A. Fisher (celui du Test de Fisher).
Elle a pris un essor considérable avec le développement de l'informatique et
la puissance de calcul qui l'accompagne.
Le traitement des résultats se fait enfin à l'aide de la régression
linéaire simple ou
multiple et l'analyse de variance.
Avec les plans d'expériences, le but est donc d'obtenir le maximum
de renseignements (mais pas tous!) avec le minimum d'expériences (et
donc le minimum de coût) dans le but de modéliser ou d'optimiser des phénomènes
étudiés.
Un expérimentateur qui lance une étude s'intéresse à une
grandeur qu'il mesure à chaque
essai. Cette grandeur s'appelle la "réponse",
c'est la grandeur d'intérêt.
La valeur de cette grandeur dépend de plusieurs variables. Au lieu du
terme "variable" on
utilisera le mot "facteur". La valeur
donnée à un facteur pour réaliser
un essai est appelée "niveau".
Lorsque l'on étudie l'influence d'un
facteur, en général, on limite ses variations entre deux bornes
(oui faut bien s'avoir s'arrêter un jour et être raisonnable...) appelées
respectivement: "niveau
bas" et "niveau haut".
Bien évidemment, lorsque nous avons plusieurs facteurs ceux-ci
représentent un point dans 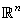 appelé alors "espace
expérimental". appelé alors "espace
expérimental".
L'ensemble de toutes les valeurs que peut prendre le facteur entre le niveau
bas et le niveau haut, s'appelle le "domaine de
variation du facteur" ou
plus simplement le "domaine du facteur".
Nous avons l'habitude de noter le niveau bas par -1 et le niveau haut par +1
quand tous les facteurs n'ont que deux niveaux, sinon est d'usage de noter
les niveaux
de 1 à n (nombre de niveaux). Bien évidemment, en fonction
de la notation choisie, il faut adapter les expressions du modèle mathématique
en conséquence.
Donc par exemple pour un facteur ayant un domaine de variation compris entre
un niveau haut de 20 [°C] correspond à +1 et un niveau bas de 5 [°C] correspondant à -1
nous devrons à la fin de notre étude transformer toutes les valeurs
expérimentales
en "unités centrées réduites" dans
lesquelles doivent être utilisées
les .
Ainsi, nous avons deux points d'entrée (20,5) et deux de sorties
(+1,-1). Toute valeur intermédiaire est donnée simplement par
l'équation
de la droite:

Figure: 74.31 - Principe de construction des unités centrées réduites
La pente est donc triviale à obtenir..., pour déterminer b,
nous avons simplement une équation à une inconnue:
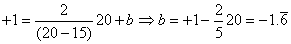 (74.292)
(74.292)
ou (ce qui revient au même):
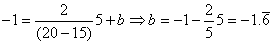 (74.293)
(74.293)
Donc le passage de variables non normalisées, notées x,
aux normalisées,
notées X, s'écrit alors:
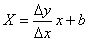 (74.294)
(74.294)
soit dans un cas de sorties (+1,-1):
 (74.295)
(74.295)
et inversement...:
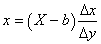 (74.296)
(74.296)
soit dans un cas de sorties (+1,-1):
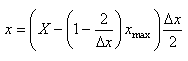 (74.297)
(74.297)
Le regroupement des domaines de tous les facteurs définit le "domaine
d'étude". Ce domaine d'étude est la zone de l'espace expérimental choisie
par l'expérimentateur pour faire ses essais. Une étude, c'est-à-dire plusieurs
expériences bien définies, est représentée par des points répartis dans le
domaine d'étude.
Par exemple, pour deux facteurs, le domaine d'étude est une surface et l'espace
expérimental est  : :

Figure: 74.32 - Exemple à deux facteurs
Les niveaux centrés
réduits représentent
les coordonnées d'un point expérimental et y est la valeur
de la réponse
en ce point. On définit un axe orthogonal à l'espace expérimental
et on l'attribue à la
réponse. La représentation géométrique du plan
d'expériences et de la réponse
nécessite un espace ayant une dimension de plus que l'espace expérimental.
Un plan à deux facteurs utilise un espace à trois dimensions
pour être représenté:
une dimension pour la réponse, deux dimensions pour les facteurs.
Lorsque nous avons déterminé le modèle mathématique,
à chaque point du domaine d'étude correspond un ensemble
de réponses qui se
localisent sur une surface appelée la "surface
de réponse" (raison pour laquelle ce domaine d'étude
est parfois appelé: "plans d'expérience pour l'estimation
de surfaces de réponse")
par exemple avec deux facteurs:

Figure: 74.33 - Deux facteurs avec la surface de réponse
Le nombre et l'emplacement des points d'expériences est le problème
fondamental des plans d'expériences. Nous cherchons à obtenir la meilleure
précision possible
sur la surface de réponse tout en limitant le nombre d'expériences!
L'ingénieur va donc rechercher une fonction mathématique
continue qui relie la réponse aux facteurs.
Pour cela, nous simplifions le problème en se rappelant (cf.
chapitre de Suites et Séries) que toute fonction quelle
que soit son nombre de variables, peut être approchée en une somme
de série
de puissance en un point donné.
Nous prenons alors un développement limité de la série
de Taylor: 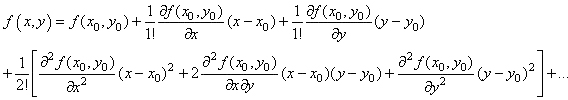 (74.298)
(74.298)
Soit autour de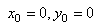 (ce
que nous pouvons nous permettre car nous prenons toujours des unités
centrées
réduites comme vues plus haut!),
nous avons la série de Maclaurin au deuxième ordre et en changeant
de notation pour (ce
que nous pouvons nous permettre car nous prenons toujours des unités
centrées
réduites comme vues plus haut!),
nous avons la série de Maclaurin au deuxième ordre et en changeant
de notation pour 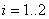 : :

(74.299)
où y est donc la réponse et les les
facteurs et les 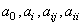 sont
les coefficients du modèle mathématique adopté a priori. Ils ne sont pas connus
et doivent être calculés à partir des résultats des expériences. sont
les coefficients du modèle mathématique adopté a priori. Ils ne sont pas connus
et doivent être calculés à partir des résultats des expériences.
L'intérêt de modéliser la réponse par un polynôme est de pouvoir calculer
ensuite toutes les réponses du domaine d'étude sans être obligé de faire les
expériences en passant par un modèle appelé "modèle
postulé" ou "modèle
a priori".
Deux compléments doivent être apportés au modèle précédemment décrit:
1. Le
premier complément est le "manque d'ajustement".
Cette expression traduit le fait que le modèle a priori est fort probablement
différent (ne
serait-ce que par l'approximation de l'approche) du modèle réel qui régit le
phénomène étudié. Il y a un écart entre ces deux modèles. Cet écart est le
manque d'ajustement ("lack of fit" en anglais).
2. Le second complément est la prise en compte de la nature aléatoire de
la réponse (sans que cette dernière soit toutefois stochastique sinon il faut
utiliser d'autres outils!). En effet, si l'on mesure plusieurs fois une réponse
en un même
point expérimental, on n'obtient pas exactement le même résultat. Les résultats
sont dispersés. Les dispersions ainsi constatées sont appelées "erreurs
expérimentales".
Ces deux écarts, manque d'ajustement et erreur expérimentale, sont souvent
réunis dans un seul écart, notée e.
Le modèle utilisé par l'expérimentateur
s'écrit alors au deuxième ordre et au premier degré:
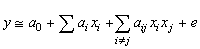 (74.300)
(74.300)
et est appelée parfois "modèle
synergique".
Remarques:
R1. Si nous prenons en compte les termes
du deuxième degré, nous parlons
alors de "modèle quadratique complet".
R2. Si nous arrêtons le développement au premier ordre et au premier degré
(sans interactions), nous parlons alors de "modèle
affine".
Dans la pratique nous notons cette dernière relation (nous enlevons
le terme d'erreur):
 (74.301)
(74.301)
où nous avons la notation abusive pour ce qui est d'suage d'appeler dans le
domaine le "terme rectangle":
 (74.302)
(74.302)
Dès lors, il vient que pour 2 facteurs, l'expression contient 4 termes, pour
3 facteurs elle contient 8 termes, pour 4 facteurs, 16 termes, etc. Il s'agit
donc toujours de puissances de 2.
Ce modèle sans erreur est souvent appelé "modèle
contrôlé avec interactions" (linéaire d'ordre
2). Par exemple, une surface de réponse associée à une relation du type précédente
est avec Maple 4.00b:
>plot3d(5+3*x1+2*x2+4*x1*x2,x1=-10..10,x2=-10..10,view=[-10..10,-10..10,-10..10],contours=10,style=PATCHCONTOUR,axes=frame,numpoints=10000);
Figure: 74.34 - Exemple générique d'interaction pour deux facteurs (paraboloïde
hyperbolique)
où nous avons représenté les isoclines (lignes dont
les réponses de la fonction
sont égales quelle que soient les valeurs des variables d'entrée).
Ce qui permet de recherche les combinaisons les moins coûteuses pour
un résultat
égal!
Évidemment, si nous supprimons les termes d'interactions, nous avons simplement
un plan:
>plot3d(5+3*x1+2*x2,x1=-10..10,x2=-10..10,view=[-10..10,-10..10,-10..10],contours=10,style=PATCHCONTOUR,axes=frame,numpoints=10000);
Figure: 74.35 - Exemple générique de modèle additif pour deux facteurs
(plan)
Évidemment, plus le degré du polynôme utilisé est élevé plus
nous avons, théoriquement, de chances d'avoir un modèle proche
de la réalité. Mais les polynômes de degré élevé réclament
beaucoup de points expérimentaux et leur validité peut vite diverger
en dehors du domaine expérimental. Si l'étude l'exige, nous préférons
utiliser des fonctions mathématiques particulières pour mieux
ajuster le modèle aux résultats expérimentaux.
Cependant, en pratique, les interactions d'ordre élevé ont
souvent une influence très faible sur la réponse (bon cette affirmation
dépend fortement du domaine d'activité...!). Il est donc possible
de ne pas les inclure dans le modèle,
ce qui conduit à faire
moins d'essais. Ce principe est utilisé dans la construction de nombreux
plans d'expériences, comme nous le verrons dans la partie suivante.
Dans de nombreuses applications, on obtient des résultats tout à fait
satisfaisants en se limitant aux interactions doubles.
Pourquoi nous satisfaisons-nous de cette relation approchée de quatre termes?
Pour la simple raison que:
1. La réponse peut être non nulle lorsque tous les facteurs sont nuls (c'est
le premier coefficient  ) )
2. La réponse dépend trivialement (intuitivement) de la somme des effets
du premier et deuxième facteurs 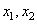 de
manière indépendante (coefficients de
manière indépendante (coefficients 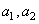 ). ).
3. La réponse dépend aussi des interactions entre les deux facteurs (coefficients 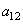 ). ).
Chaque point expérimental dont les sont
données permet alors d'obtenir une valeur de la réponse y. Cette
réponse est modélisée par un polynôme dont les coefficients sont les inconnues
qu'il faut déterminer.
PLANS FACTORIELS COMPLETS
Donc dans un plan d'expérience de 2 facteurs à 2 niveaux, nous avons besoin
d'au moins (et au plus pour des raisons de coûts!) de 4 mesures pour avoir
un système
de quatre équations à quatre inconnues qui sont les coefficients 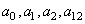 . .
Remarque:
Pour une étude de 2 facteurs à 3 niveaux, nous ne pouvons plus prendre le modèle
linéaire. Il nous faut alors prendre les termes quadratiques du développement
de Taylor.
Puisque pour chacun des facteurs nous devons nous fixer
un niveau bas et un niveau haut pour pouvoir travailler raisonnablement...
alors si nous avons deux facteurs, nous avons un espace expérimental
défini par 4
points {(haut, haut), (bas, bas), (haut, bas), (bas,haut)}, correspondant aux
2 fois 2 niveaux ( ),
qui nous suffit pour obtenir alors nos 4 équations à 4
inconnues et alors de déterminer les 4 coefficients. ),
qui nous suffit pour obtenir alors nos 4 équations à 4
inconnues et alors de déterminer les 4 coefficients.
Ainsi, les points à prendre pour notre expérience correspondent naturellement
aux sommets (géométriquement parlant) de l'espace expérimental.
Nous avons alors le système d'équations (rappelons que cette
approche ne fonctionne que pour des facteurs ayant 2 niveaux, le cas à trois
niveaux étant traité bien plus loin avec un exemple):
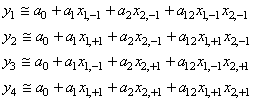 (74.303)
(74.303)
ou explicitement écrit:
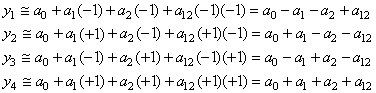 (74.304)
(74.304)
Comme, nous nous intéressons aux coefficients (et que les variables
sont connues!), il s'agit en fait simplement de résoudre un système
linéaire (cf.
chapitre d'Algèbre Linéaire).
Si les variables n'étaient
pas codées, nous aurions par exemple pour un plan factoriel complet à deux
niveaux avec une variable (vitesse du véhicule) ayant pour valeur
basse 40 [km/h]
et pour valeur haute 50 [km/h], ainsi qu'une deuxième
variable (pression de pneus) ayant pour valeur basse 1.5 [Pa] et
pour valeur haute 3 [Pa]
le système suivant à résoudre sachant que nous avons
obtenu respectivement pour chaque combinaison les distances parcourues suivantes
32'700,
32'680,
31'710
33'220 [km]:
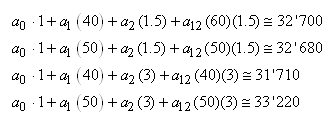 (74.305)
(74.305)
Soit sous forme matricielle:
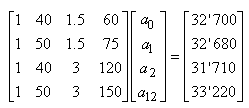 (74.306)
(74.306)
En résolvant ce système à la main (cf.
chapitre d'Algèbre
Linéaire), ou avec un logiciel de calcul (tableur ou logiciel de statistiques),
nous obtenons:
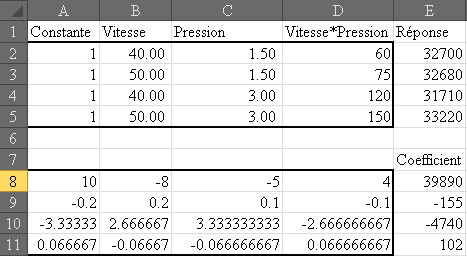
Figure: 74.36 - Mise en équation et résolution implicite sous la version
anglaise de Microsoft
Excel 14.0.6123
soit explicitement:
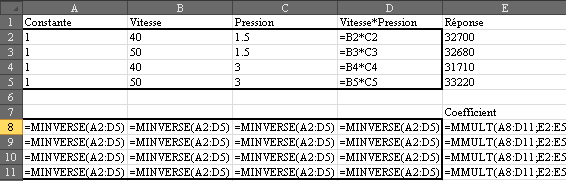
Figure: 74.37 - Mise en équation et résolution explicite sous la version
anglaise de Microsoft
Excel 14.0.6123
Donc la fonction est finalement:
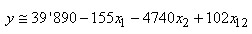 (74.307)
(74.307)
soit exactement les mêmes coefficients que ce que nous donne
un logiciel spécalisé comme Minitab 15.1.1.
Pour en revenir à notre système avec les variable codées,
il vient alors en résolvant
le système algébriquement
(relations valables que si et seulement si les variables sont codées!):
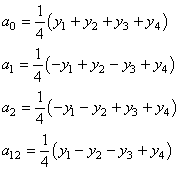 (74.308)
(74.308)
qui peut s'écrire sous la forme matricielle suivante:
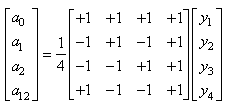 (74.309)
(74.309)
Ce qui s'écrit de manière générale pour des modèles linéaires du deuxième
ordre sous la forme générale (cf. chapitre d'Algèbre Linéaire):
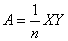 (74.310)
(74.310)
La matrice X contenant  lignes
est appelée "plan factoriel complet (PFC)
2n avec
interactions" (le
terme "factoriel" venant du fait que tous les facteurs varient simultanément). lignes
est appelée "plan factoriel complet (PFC)
2n avec
interactions" (le
terme "factoriel" venant du fait que tous les facteurs varient simultanément).
La matrice X dans la pratique est appelée "matrice
d'expérimentation" ou
encore "matrice des effets" et est souvent représentée de la manière
suivante dans le cas particulier précédent:
Essai
n° |
Repos |
Facteur
1 |
Facteur
2 |
Facteur
12 |
Réponse |
1 |
+1 |
-1 |
-1 |
+1 |

|
2 |
+1 |
+1 |
-1 |
-1 |

|
3 |
+1 |
-1 |
+1 |
-1 |

|
4 |
+1 |
+1 |
+1 |
+1 |

|
Tableau: 74.14
- Matrice d'expérimentation
Mais l'on voit tout de suite que dans la pratique, la deuxième colonne
(Repos)
est inutile, car elle vaut toujours +1 et elle est implicitement implémentée
dans les logiciels.
Il en est de même pour la cinquième colonne (Facteur 12), car
elle se déduit automatiquement de la troisième et quatrième
colonnes (c'est la multiplication des termes ligne par ligne... ce que certains
appellent la "multiplication
de Box").
Le lecteur remarquera aussi qu'en passant d'une colonne à l'autre ou
d'une ligne à l'autre, il y a toujours deux facteurs qui changent
de niveau! Par contre, si nous nous concentrons uniquement sur les colonnes Facteur 1
et Facteur 2, nous voyons qu'en passant d'une ligne à l'autre,
il n'y a qu'un facteur qui change à la fois.
Remarque: Observez donc que la première colonne vaut toujours +1 et il y
a toujours aussi une ligne avec uniquement des +1!
Ainsi, dans la pratique (logiciels) et dans de nombreux ouvrages, on représente à juste
titre uniquement le tableau suivant (ce qui masque le fait que nous avons affaire à une
matrice carrée):
Essai
n° |
Facteur
1 |
Facteur
2 |
Réponse |
1 |
-1 |
-1 |
|
2 |
+1 |
-1 |
|
3 |
-1 |
+1 |
|
4 |
+1 |
+1 |
|
Tableau: 74.15
- Matrice d'expérimentation simplifiée
pour un plan d'expérience de 2 facteurs à 2 niveaux avec interactions
en modèle
linéaire (sans erreur) nous avons encore plus extrême ("notation
de Yates")... en
termes d'écriture:
Essai
n° |
Facteur
1 |
Facteur
2 |
Réponse |
1 |
- |
- |
|
2 |
+ |
- |
|
3 |
- |
+ |
|
4 |
+ |
+ |
|
Tableau: 74.16
- Matrice d'expérimentation avec notation de Yates
Nous voyons que dans cette forme d'écriture qu'outre le fait que les
deux colonnes Facteur 1
et Facteur 2 sont orthogonales (la norme ISO 3534-3:1999 parle
de "contraste orthogonal"), elles sont aussi "balancées",
dans le sens qu'il y a autant de + et de - dans chacune des colonnes.
Remarque: Par défaut, la majorité des
logiciels randomise l'ordre des essais du plan (qu'il soit complet, fractionnaire,
factoriel ou non). En
règle générale, il est recommandé de randomiser
l'ordre des essais pour atténuer les effets des facteurs qui ne
sont pas inclus dans l'étude et qui parasitent cette dernière, notamment
les effets liés
au temps. Cependant, dans certains cas, la randomisation ne produit pas
un
ordre des
essais intéressant et peut être même dangereux car elle
peut masquer certaines sources d'erreurs systématiques qui n'avaient
pas été identifiées
avant l'expérience. Par exemple, dans les applications industrielles,
la modification des niveaux
de facteurs
peut
s'avérer
difficile ou coûteuse.
Il est également possible qu'une fois la modification effectuée,
le retour du système à un état constant prenne beaucoup
de temps. En pareil cas, il peut être souhaitable de ne pas randomiser
le plan afin de limiter au maximum les modifications de niveau.
Les praticiens apprécient de calculer la moyenne des réponses
et l'effet moyen d'un facteur donné puisque le système est linéaire.
Ainsi, au niveau +1 pour le facteur 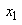 ,
en nous basant toujours sur le système linéaire: ,
en nous basant toujours sur le système linéaire:
(74.311)
nous pouvons alors construire et définir
la "moyenne
des réponses" donnée par:
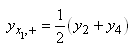 (74.312)
(74.312)
et il vient de même au niveau -1 toujours pour le même facteur:
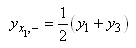 (74.313)
(74.313)
Nous avons alors "l'effet global" du
facteur qui
sera donné par :
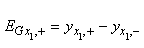 (74.314)
(74.314)
et "effet moyen" du facteur qui
est alors défini par la demi-différence entre la moyenne des réponses au niveau
haut du facteur et
la moyenne des réponses au niveau bas du même facteur:
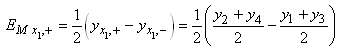 (74.315)
(74.315)
or après quelques simplification d'algèbre élémentaire, il vient
très rapidement que:
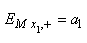 (74.316)
(74.316)
Il est évident que si l'effet global (et in extenso l'effet
moyen) est non nul, nous pouvons nous douter qu'il y a une interaction entre
les facteurs
puisque la variation d'amplitude de la réponse n'est pas identique en
fonction de la valeur du niveau de l'autre facteur (voir l'étude
de l'analyse de la variance à deux
facteurs dans le chapitre de Statistiques pour plus de détails). Évidemment,
dans la pratique, l'étude des interactions se fera en tout rigueur
comme souvent pour l'ANOVA: avec des graphiques.
La moyenne de toutes les réponses donne donc la valeur
de la réponse au centre du domaine expérimental:
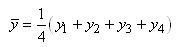 (74.317)
(74.317)
En faisant un peu d'alèbre élémentaire,
que le plan soit écrit
sous forme normalisée et centrée ou non, cette dernière
expression se réduit à:
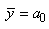 (74.318)
(74.318)
Évidemment, nous pouvons résumer ce cas simple sous forme graphiqu
si cela peut aider le lecteur:

Figure: 74.38 - Deux facteurs avec la surface de réponse
et avec la figure ci-dessus, la variations n'étant pas très parallèles lorsqu'un
facteur est fixé, nous pouvons supposer qu'il y a interaction entre les facteurs
qui nécessiteront l'utilisation d'une ANOVA.
Lorsque le nombre de facteurs est grand, il n'est pas toujours facile pour
tout le monde de poser rapidement les facteurs +, - sans l'aide d'un logiciel.
Alors, il existe une petite marche à suivre appelée "algorithme
de Yates" ou "algorithme de Yates
et Hunter" qui
permet vite d'arriver au résultat voulu pour les plans factoriels
(dont les facteurs ont deux niveaux) dont le nombre de facteurs est une puissance
de 2:
D'abord, nous commençons toutes les colonnes par -1 et nous alternons les
-1 et les +1 toutes les 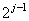 lignes
pour la j-ème colonne. lignes
pour la j-ème colonne.
Remarques:
R1. Si le type de tableau précédent contient des valeurs codées, nous parlons
de "plan d'expérience" sinon avec les unités physiques habituelles
nous parlons de "tableau d'expérimentation".
R2. Dans le cas des tableaux codés, il est d'usage d'indiquer sous le tableau
un deuxième tableau avec les correspondances entre les unités codées et les
unités physiques.
Insistons sur une chose importante: C'est que si nous avions 3 facteurs à 2
niveaux, alors nous avons  possibilités
d'expériences (soit 8). Or, huit correspond exactement au nombre de
coefficients que nous avons également dans le modèle linéaire
avec interactions d'une réponse à trois
variables: possibilités
d'expériences (soit 8). Or, huit correspond exactement au nombre de
coefficients que nous avons également dans le modèle linéaire
avec interactions d'une réponse à trois
variables:
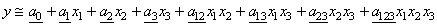 (74.319)
(74.319)
ce qui correspond aussi aux termes seulement linéaires et sous forme condensée
du développement en série de Maclaurin d'une fonction f de trois variables.
Et ainsi de suite... pour n facteurs à deux niveaux. C'est la raison
pour laquelle les plans factoriels complets linéaires sont
traditionnellement les plus utilisés car ils sont mathématiquement
intuitifs et simples à démontrer.
Par ailleurs, il est important de remarquer que tous ces plans linéaires
complets approximés au deuxième ordre sont sous forme matricielles des matrices
carrées  orthogonales
et donc bien évidemment inversibles (cf. chapitre d'Algèbre Linéaire)! orthogonales
et donc bien évidemment inversibles (cf. chapitre d'Algèbre Linéaire)!
Cependant les matrices précédentes ne satisfont pas la relation
suivante vue dans le chapitre d'Algèbre Linéaire (produit scalaires
des colonnes-bases avec elles-mêmes et de vecteurs orthogonaux):
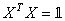 (74.320)
(74.320)
mais ont pour particularité pour tout plan d'expérience complet de satisfaire
la relation:
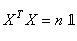 (74.321)
(74.321)
Donc contrairement aux matrices orthogonales qui par définition ont toutes
les colonnes (ou lignes) qui forment une base orthonormée (norme unitaire),
les matrices des plans d'expérience ont pour différence de ne pas avoir les
normes de la base orthogonale à l'unité.
Ainsi, nous définissons la matriceA dont les coefficients
sont tous des +1 ou des -1 ET satisfaisant la relation précédente
comme étant une "matrice
de Hadamard". Cette dernière a par ailleurs pour
propriété d'exister
que pour les ordres 1, 2, 4, 8, 12, 16, 20, 24, ... C'est-à-dire
uniquement pour les ordres multiple de 4 (si nous omettons l'ordre 1 et
2).
Démonstration:
Sachant que les cas d'ordre 1 et 2 sont triviaux et que les cas impairs sont à éliminer
intuitivement immédiatement (essayez et vous verrez très vite...), faisons
la démonstration
pour 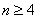 . .
Puisque toutes les colonnes doivent être
obligatoirement orthogonales (pour que la matrice soit inversible et donc le
système
résoluble),
nous pouvons toujours écrire le problème sous la forme (forme
particulière pour n valant
4 mais facilement généralisable):
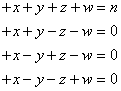 (74.322)
(74.322)
et si nous notons n comme étant l'ordre de la matrice. Alors
nous avons par sommation de toutes les lignes:
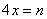 (74.323)
(74.323)
donc n doit être divisible par 4 pour pour
que toutes les colonnes soient orthogonales et donc que la matrice soit de
Hadamard sachant que x, y, z, w ont pour valeur
1.
Pour les lecteurs qui doutent concernant les valeurs paires: 6, 10, 14, 18,
etc. Essayez de trouver une matrice de Hadamard à la main dont tous les vecteurs
sont orthogonaux deux à deux... vous verrez très vite que vous allez coincer.
C.Q.F.D.
Il s'ensuit alors trivialement la relation suivante (avec une notation très
abusive car on omet la notation de la matrice unité):
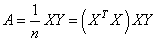 (74.324)
(74.324)
Cependant, nous verrons un tout petit peu plus loin lors
de notre étude des plans factoriels fractionnaires que les matrices
d'Hadamard d'ordre 1, 4, 8, 16, 32, ..., 2n ne sont
quasiment jamais utilisées
sous l'expression de "matrices d'Hadamard" car elles se confondent
avec les plans factoriels
fractionnaires.
Par contre, il est intéressant de constater que nous
avons des plans d'expérience possibles avec 12, 20, 24, 28, ...
essais qui ont un intérêt certain lorsque le nombre de facteurs
est supérieur
ou égal 4 (certains logiciels comme JMP ne les proposent pas cependant
si le nombre de facteurs est inférieur à cinq). Ces plans sont
appelés "plans
de Plackett-Burman" et
parfois "plans irréguliers de Plackett-Burman" ou
encore plus rarement "plans
non-géométriques de Plackett-Burman" (un logiciel
comme Minitab propose cependant arbitrairement - et l'indique explicitement
ainsi
dans l'aide du logiciel - un plan de Plackett-Burman d'ordre 32 et des
plans de Plackett-Burman même pour 2 ou 3 facteurs).
Plackett et Burman ont cherché avec des algorithmes
et par tatonnement l'expression des matrices d'expériences correspondant
aux plans qui portent leur nom et qui contiennent donc 12, 20, 24, 28, etc.
essais. Ils ont proposé une astuce fort utile pour que les praticiens
puissent faire usage de ces plans sans logiciels. Faisons l'exemple pour commencer
avec une matrice
de Hadamard d'ordre 12 (sans s'occupper pour l'instant du nombre de facteurs
que nous allons utiliser). Les tables de Plackett-Burman (ou les logiciels)
donnent uniquement la première ligne:
+ + - + + + - - - + -
Ensuite, nous construisont la table d'expérience suivante
en suivant l'algorithme proposé par Plackett et Burman (les logiciels
utilisent le même):
- Première étape, nous mettons la première
ligne sous forme de colonne dans un tableau de 12 par 12:
Tableau: 74.17 - Première étape de construction du plan de Plackett- Burman
- Deuxième étape, nous déduisons
la deuxième colonne à partir de cette première colonne en décalant les signes
d'un cran vers la bas, le dernier signe "-" étant, lui, remonté au sommet
de la deuxième colonne (il s'agit donc d'une permutation circulaire):
+
|
- |
|
|
|
|
|
|
|
|
|
|
+
|
+ |
|
|
|
|
|
|
|
|
|
|
-
|
+ |
|
|
|
|
|
|
|
|
|
|
+
|
- |
|
|
|
|
|
|
|
|
|
|
+
|
+ |
|
|
|
|
|
|
|
|
|
|
+
|
+ |
|
|
|
|
|
|
|
|
|
|
-
|
+ |
|
|
|
|
|
|
|
|
|
|
-
|
- |
|
|
|
|
|
|
|
|
|
|
-
|
- |
|
|
|
|
|
|
|
|
|
|
+
|
- |
|
|
|
|
|
|
|
|
|
|
-
|
+ |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
Tableau: 74.18 - Deuxième étape de construction du plan de Plackett-Burman
et ainsi de suite jusqu'à la 11ème colonne:
+
|
-
|
+
|
-
|
-
|
-
|
+
|
+
|
+
|
-
|
+
|
|
+
|
+
|
-
|
+
|
-
|
-
|
-
|
+
|
+
|
+
|
-
|
|
-
|
+
|
+
|
-
|
+
|
-
|
-
|
-
|
+
|
+
|
+
|
|
+
|
-
|
+
|
+
|
-
|
+
|
-
|
-
|
-
|
+
|
+
|
|
+
|
+
|
-
|
+
|
+
|
-
|
+
|
-
|
-
|
-
|
+
|
|
+
|
+
|
+
|
-
|
+
|
+
|
-
|
+
|
-
|
-
|
-
|
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
-
|
+
|
-
|
-
|
|
-
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
-
|
+
|
-
|
|
-
|
-
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
-
|
+
|
|
+
|
-
|
-
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
-
|
|
-
|
+
|
-
|
-
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
Tableau: 74.19 - 3ème à 11ème étape de construction
du plan
de Plackett-Burman
- Dernière étape, nous ajoutons une rangée
et une colonne de signes "-":
+ |
- |
+ |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
- |
+ |
+ |
- |
+ |
- |
- |
- |
+ |
+ |
+ |
- |
- |
- |
+ |
+ |
- |
+ |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
- |
+ |
+ |
- |
+ |
- |
- |
- |
+ |
+ |
- |
+ |
+ |
- |
+ |
+ |
- |
+ |
- |
- |
- |
+ |
- |
+ |
+ |
+ |
- |
+ |
+ |
- |
+ |
- |
- |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
+ |
- |
+ |
- |
- |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
+ |
- |
+ |
- |
- |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
+ |
- |
+ |
- |
+ |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
+ |
- |
- |
- |
+ |
- |
- |
- |
+ |
+ |
+ |
- |
+ |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
Tableau: 74.20 - Dernière étape de construction
du plan de Plackett-Burman
Le lecteur pourra facilement vérifier que chaque ligne
ou chaque colonne prises deux à deux sont bien orthogonales.
Maintenant se pose à la question de savoir si nous choisissons
d'associer par exemple ce plan d'expérience à un plan à 4
facteurs (sous-entendu centrés réduits bien évidemment!):
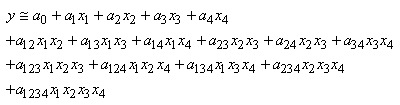 (74.325)
(74.325)
pour réduire le nombre d'essais de 16 à
12 à quelle colonne devons nous associer à quoi? Ou encore
en allant plus loin: pour combien de facteurs pouvons nous associer ce type
de plan à 12 essais pour des facteurs à deux niveaux?
Eh bien il y a deux grandes religions (maisons) suivant
les ingénieurs.
- La première consiste à dire que les plans
de Plackett-Burman d'ordre n ne doivent être utilisés
que pour l'étude des
effets principaux (donc aucune interaction ne sera prise en compte) de n-1
facteurs. Ainsi, un plan de Plackett & Burmann d'ordre 12, sera réservé pour
une étude de 11 facteurs et uniquement de leurs effets principaux
(modèle
linéaire purement additif).
- La deuxième consiste à dire que les plans
de Plackett- Burman contiennent un concept que nous verrons plus loin
et qui s'apelle
les "alias" (les plans de Plackett-Burman sont tous des plans de
résolution III au deuxième ordre). Par
conséquent,
il faut utiliser ce type de plan que lorsque nous sommes prêts à considérer
dans un premier temps que les interactions à deux facteurs sont très
négligeables.
La complexité des alias avec les plans de Plackett-
Burmann fait que dans la pratique, ils sont finalement plutôt utilisé selon
la première religion... par les débutants et selon la seconde
par les consultants.
Remarque: Un logiciel comme Minitab 15.1.1 n'affiche
pas du tous les alias utilisés lors de l'application de plans de Placket
et Burmann.
Pour clore cette
partie, résumons
un constat simple:
Plan |
Facteurs |
Interactions |
Somme |
|
2 |
1 |
3 |
|
3 |
4 |
7 |

|
4 |
11 |
15 |

|
5 |
26 |
31 |

|
6 |
57 |
63 |

|
7 |
120 |
127 |
... |
... |
... |
... |
Tableau: 74.21 - Types de plans avec facteurs & interactions
Donc en utilisant les plans factoriels complets, l'utilisateur est sûr d'avoir
la procédure expérimentale optimale puisque ces plans sont basés sur des matrices
d'Hadamard et qu'il a été démontré que nous ne pouvions pas faire mieux.
PLANS FACTORIELS FRACTIONNAIRES
En pratique, les plans complets ne sont utilisables que sur des systèmes
avec très peu de facteurs, ou lorsque chaque essai prend très
peu de temps. Lorsque n est
plus grand ou égal
3 alors les coûts
des expériences
peut très vite devenir onéreux.
Le plus petit cas où il est intéressant d'optimiser le nombre d'essais et
celui consistant en 3 facteurs à 2 niveaux. Nous avons alors l'équation
et le tableau d'expérience
suivant:

Essai
n° |
Facteur
1 |
Facteur
2 |
Facteur
3 |
Réponse |
1 |
- |
- |
- |
|
2 |
+ |
- |
- |
|
3 |
- |
+ |
- |
|
4 |
+ |
+ |
- |
|
5 |
- |
- |
+ |

|
6 |
+ |
- |
+ |

|
7 |
- |
+ |
+ |

|
8 |
+ |
+ |
+ |

|
Tableau: 74.22
- Plan d'expérience à 3 facteurs complet sous forme de Yates
Soit sous forme de tableau d'expérience complet:
Essai
n° |
Repos |
F 1 |
F 2 |
F 3 |
F 12 |
F 13 |
F 23 |
F 123 |
Réponse |
1 |
+ |
- |
- |
- |
+ |
+ |
+ |
- |
|
2 |
+ |
+ |
- |
- |
- |
- |
+ |
+ |
|
3 |
+ |
- |
+ |
- |
- |
+ |
- |
+ |
|
4 |
+ |
+ |
+ |
- |
+ |
- |
- |
- |
|
5 |
+ |
- |
- |
+ |
+ |
- |
- |
+ |
|
6 |
+ |
+ |
- |
+ |
- |
+ |
- |
- |
|
7 |
+ |
- |
+ |
+ |
- |
- |
+ |
- |
|
8 |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
|
Tableau: 74.23
- Plan d'expérience à 3 facteurs et interactions complet sous
forme
de
Yates
ou de matrice d'expérience complète:
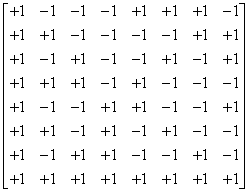 (74.326)
(74.326)
où à nouveau il est facile de contrôler que toutes les colonnes
sont orthogonales et balancées (même nombre de + ou de - dans chaque
colonne ou autrement dit la somme de leurs colonnes est nulle) et que la matrice
est bien de type
Hadamard. Ainsi, un plan factoriel complet pour 3 facteurs implique 8 essais.
Nous pouvons également représenter tout cela sous forme graphique:

Figure: 74.39 - Représentation traditionnelle d'un plan factoriel fractionnaire complet
à 3 facteurs
Les plans réduits (plans factoriels fractionnaires) ou "plans
de screening"
(selon la norme ISO 3534-3:1999), consistant à sélectionner
certaines combinaisons, ont donc été proposés. Ils permettent
naturellement de réduire les coûts, mais diminuent également
l'information disponible sur le comportement du système! Il faut donc
s'assurer de la pertinence de la sélection par rapport au modèle à identifier.
Une première méthode élémentaire est par exemple
de faire l'hypothèse qu'il
n'y a aucune interaction. Dès lors, notre fonction se réduit à un
modèle purement additif:
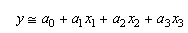 (74.327)
(74.327)
et pour résoudre ce système, il nous suffit d'avoir 4 essais.
Nous passons ainsi de 8 à 4 essais en supposant qu'il n'y a pas d'interactions
et nous nous retrouvons avec un simple plan de criblage.
Pour réduire les coûts d'expérimentation tout en gardant les
interactions implicitement, nous pouvons jouer avec la mathématique.
D'abord reprenons le problème
actuel avec un plan factoriel de 3 facteurs complet sous forme
explicite:
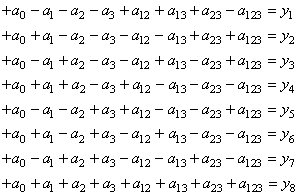 (74.328)
(74.328)
Pouvons-nous en réduire l'écriture afin de minimiser le
nombre d'expériences à faire?
La réponse est: Oui mais en contre partie nous allons perdre la
mesure des effets purs (nous parlons alors parfois de "confusion").
L'écriture inférieure la plus proche est une matrice de Hadamard d'ordre
4. Ce qui signifie bien évidemment que nous ne devons conserver 4 lignes sur
les 8 et que celles-ci doivent rester orthogonales, balancées et satisfaire
la relation:
(74.329)
L'idée, appelée "méthode
de Box et Hunter" et qui ne marche que pour les plans avec des
facteurs ayant deux niveaux, est alors dans un premier temps de rassembler
les facteurs d'influence (en
indices)
tel
que (développements similaires
pour tout n):
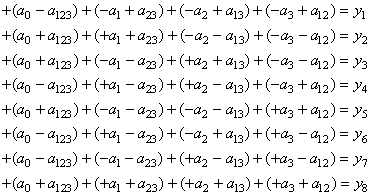 (74.330)
(74.330)
Le choix du regroupement est aussi fait en sorte que les
coefficients des interactions supposeés négligeables de par
la normalisation centrée réduite
se retrouvent avec un coefficient d'un facteur principal supposé comme
non négligeable. Dès lors, il est aussi logique que dans
chaque regroupement, on ne retrouve jamais en indice le numéro du
facteur principal.
Nous disons alors que nous avons une structure d'alias (la norme
ISO 3534-3:1999 appelle cela une "concomitance" lorsque c'est l'expérimentateur
qui force le regroupement et "alias" si la confusion est due à la
nature de l'expérience) du type:
0+123;1+23;2+13;3+12
et si nous notons cela comme le font de nombreux logiciels
de statistiques, cela donne (c'est exactement les alias que donne un logiciel
comme Minitab 15.1.1):
I+ABC;A+BC;B+AC;C+AB
Ou certains notent cela (car I doit toujours avoir un signe
positif):
I=ABC;A+BC;B+AC;C+AB
Écrivons cela de la manière suivante:
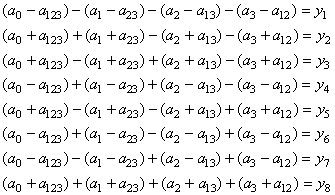 (74.331)
(74.331)
Changeons de notation:
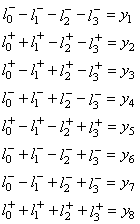 (74.332)
(74.332)
Tout naturellement, si nous considérons cette nouvelle notation comme
des variables propres, ce système unique se sépare maintenant
en deux sous-systèmes
(les regroupements étant respectivement appelés des "contrastes" dans
le domaine mais cela n'est pas conforme à la définition de la norme ISO 3534-3)
pour être
résoluble:
 et et  (74.333)
(74.333)
ce qui permet de diviser le nombre d'essais par deux par rapport à un
plan complet. En résolvant un de ces deux systèmes, nous
disons que les interactions sont "aliasées" (dit
aussi en "confusion") avec les effets purs en négatif
ou en positif (dans le cas présent,
certains effets principaux sont confondus avec des interactionsà deux facteurs).
Il est ensuite de tradition de garder que le système aliasé positivement:
(74.334)
car si les interactions sont nulles, nous retrouvons à l'identique
la matrice d'expérience d'un plan factoriel complet !
La démarche conduit donc à ne sélectionner que les
essais 2, 3, 5 et 8, ce qui permet de diviser le nombre d'essais par deux
par rapport à un
plan complet. Ainsi, un plan factoriel fractionnaire d'une expérience à 3
facteurs peut
être réduit à 4 essais avec cette méthode. Le plan
factoriel fractionnaire ci-dessus sera représenté naturellement
par la matrice d'expérience
suivante:
Essai
n° |
Facteur
1 |
Facteur
2 |
Facteur
3 |
Réponse |
2 |
+ |
- |
- |
|
3 |
- |
+ |
- |
|
5 |
- |
- |
+ |
|
8 |
+ |
+ |
+ |
|
Tableau: 74.24 - Plan d'expérience fractionnaire à 3 facteurs complet sous
forme
de
Yates
Il y a cependant un problème : Même si l'interaction triple
est réellement nulle, il peut rester jusqu'à 7 autres coefficients
dans le modèle, alors que l'on ne dispose que de 4 résultats
d'essais pour les identifier. Autrement dit, à moins que l'on sache
a priori qu'au moins 3 de ces coefficients sont nuls (afin de se ramener à
quatre équations avec 4 inconnues), on n'obtiendra au mieux que des
relations entre les coefficients et l'identification rigoureuse
sera
impossible. Ainsi, il n'est pas possible de réduire indéfiniment
le coût d'une étude expérimentale sans en dégrader
la robustesse.
Il
est important d'observer que dans la plan factoriel fractionnaire ci-dessus,
le troisième
facteur est confondu (peut être assimilé) avec l'interaction 12
des facteurs 1 et 2.
Nous appelons cela "l'alias initiale" ou
le "générateur" et
nous pouvons remarquer en réitérant
les calculs pour des plans factoriels à
4, 5, 6 ... facteurs que les générateurs permettent d'identifier
immédiatement les essais à préserver (par ailleurs
vous pouvez contrôler que lorsque les logiciels Minitab ou JMP
vous imposent les générateurs, ils prennent par défaut
les théoriques).
Par exemple, le générateur ("alias" ou "confusion") du
tableau ci-dessus s'écrira
selon la tradition:
C = AB
Cela ne signifie cependant pas que les coefficient du modèle seront égaux
mais que simplement le plan est incapable de dissocier l'analyse des ces
deux entités. Il faudra donc faire particulièrement attention à l'interprétation
des coefficients respectifs.
Nous venons donc de voir qu'un plan 2(3-1) présente le sérieux
inconvénient
de confondre un facteur principal avec une interaction d'ordre 2. Un
plan 2(4-1) présente seulement l'inconvénient
de confondre un facteur principal avec une interaction d'ordre 3 et deux
interactions d'ordre
2 entre elles. Un plan 2(5-1) présente
des inconvénients encore moindres. C'est pour cette raison que la théorie
des plans factoriels utilise la notion de résolution. Plus la résolution
est grande, plus le plan
est précis.
Définitions:
D1. Lorsqu'aucun effet principal ne possède d'alias avec un autre
effet principal,
mais les effets principaux possèdent des alias avec des interactions à 2
facteurs, nous parlons de "plan de résolution
III". D'un point de vue pratique les plans de résolution
III ont surtout pour but de permettre des recherches exploratoires car ils permettent
d'explorer un grand nombre de facteurs avec une économie certaine. À défaut
d'obtenir un modèle suffisamment précis ils permettent éventuellement
d'éliminer un grand nombre de facteurs dans un premier temps.
D2. Lorsqu'aucun effet principal ne possède d'alias avec un autre effet
principal
ou une autre interaction à 2 facteurs, mais certaines des interactions à 2
facteurs possèdent des alias avec d'autres interactions à 2 facteurs
et des effets principaux possèdent des alias avec des interactions à 3
facteurs, nous parlons de "plan de résolution
IV".
D3. Lorsqu'aucun effet principal ou aucune interaction à 2 facteurs ne
possède
d'alias avec un autre effet principal ou une autre interaction à 2 facteurs,
mais des interactions à 2 facteurs possèdent des alias avec des
interactions à 3 facteurs et des effets principaux possèdent des
alias avec des interactions à 4 facteurs, nous parlons de "plan
de résolution
V".
et ainsi de suite...
Ce concept de résolution est important. Nous le retrouvons dans
des logiciels comme Minitab 15.1.1 lors de sélection de plans
factoriels fractionnaires avec les alias les plus fréquents connus sous
le nom de "plans d'expériences avec abérration
minimale" ("minimum aberration
designs" en anglais):
Figure: 74.40 - Affichage des choix de résolutions de plans factoriels fractionnaires
dans Minitab 15.1.1
ou encore avec le logiciel Design Experts (partie du tableau mais qui est
plus explicite que Minitab 15.1.1):
Figure: 74.41 - Affichage des choix de résolutions de plans factoriels fractionnaires
dans Design Experts
Ainsi, le lecteur pourra observer qu'un plan completer de 5 facteurs à 32
essais peut être réduit à 16 essais en rassemblant les
facteurs d'influence par paires ou 2-uplets (d'où la division par deux
du nombre d'essais), ou encore
à 8 essais en rassemblant les facteurs d'influence par 4-uplets.
Ensuite, c'est à l'expérimentateur de bien connaître son
analyse et de savoir si:
1. Parmi les facteurs aliasés s'il y a des interactions ou non!
2. Dans le facteur aliasé l'influence forte sur la réponse vient de l'interaction
ou de l'effet pur seul!
Une fois les coefficients déterminés, sous l'hypothèse que chacun des facteurs
ou interactions est indépendant (hypothèse limite acceptable...) certains ingénieurs
font une analyse de la variance de la droite de régression obtenue au final
ou déterminent le coefficient de corrélation afin de déterminer si l'approximation
linéaire du modèle est acceptable dans le domaine d'étude et d'application.
Concernant les générateurs des plans factoriels fractionnaires
voici un petit tableau récapitulatif non exhaustif:
Facteurs |
Essais |
Résolution |
|
Générateurs |
Alias
|
3 |
4 |
III |
2(3-1)
|
C=AB |
I+ABC,A+BC, B+AC, C+AB
|
4 |
8 |
IV |
2(4-1)
|
D=ABC |
I+ABCD, A+BCD, B+ACD, C+ABD, D+ABC,
AB+CD, AC+BD, AD+BC
|
5 |
8 |
III |
2(5-2)
|
D=AB, E=AC |
I+ABD+ACE+BCDE
A+BD+CE+ABCDE
B+AD+CDE+ABCE
C+AE+BDE+ABCD
D+AB+BCE+ACDE
E+AC+BCD+ABDE
BC+DE+ABE+ACD
BE+CD+ABC+ADE
|
|
16 |
V |
2(5-1)
|
E=ABCD |
A+BCDE
B+ACDE
C+ABDE
D+ABCE
E+ABCD
AB+CDE
AC+BDE
AD+BCE
AE+BCD
BC+ADE
BD+ACE
BE+ACD
CD+ABE
CE+ABD
DE+ABC
|
...
|
|
|
|
|
|
Tableau: 74.25 - Quelques plans factoriels fractionnaies avec générateurs et alias
Bien évidemment, utiliser des plas fractionnaires est un pari économique
(et temporel). Si les conclusions sont claires, nous avons alors gagné du
temps et réduit notre effort. Mais il arrive que l'on perde le pari.
Nous pouvons dès lors utiliser un "plan complémtenaire" qui consiste à ajouter
de manière pertinente suffisamment de lignes au plan initiale pour désaliaser
les coefficients désirés sur la base du choix du générateur
d'alias.
Avant de passer à un autre type de plan, revenons juste sur le plan
factoriel fractionnaire à 3 facteurs donc avec 4 essais pour des raisons
pédagogiques.
Considérons que nous avons fait ces 4 essais et que pour chacun, nous
avons obtenu une mesure donnée dans la figure ci-dessous:

Figure: 74.42 - Représentation d'un plan factoriel fractionnaire réél à 3 facteurs
Nous voulons montrer au lecteur non pas comment déterminer le
calcul des coefficients (résolution d'un simple système linéaire et puis il
y aura un exemple à ce propos un peu plus loin) mais comment calculer les effets
dans le cadre de ce cas particulier.
Ainsi, l'effet de est:
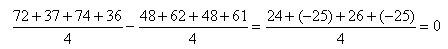 (74.335)
(74.335)
et celui de 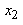 est: est:
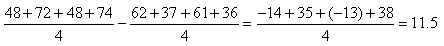 (74.336)
(74.336)
et celui de  est: est:
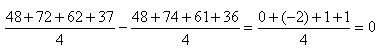 (74.337)
(74.337)
L'effet des interactions est un peu subtile dans le cas de
3 facteurs en utilisant la figure ci-dessous (nous verrons dans l'exemple
plus bas qu'avec
un tableau c'est beaucoup plus intuitif). Ainsi, nous avons pour l'interaction  : :
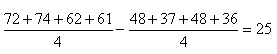 (74.338)
(74.338)
et pour  : :
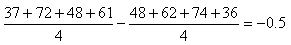 (74.339)
(74.339)
et pour  : :
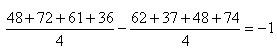 (74.340)
(74.340)
Pour l'interaction triple  avec
la figure ci-dessous ce n'est pas non plus trivial (cela l'est un peu plus
avec un table comme nous le verrons dans l'exemple plus bas). Nous avons: avec
la figure ci-dessous ce n'est pas non plus trivial (cela l'est un peu plus
avec un table comme nous le verrons dans l'exemple plus bas). Nous avons:
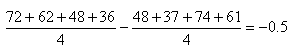 (74.341)
(74.341)
PLANS ET NOMENCLATURE DE TAGUCHI
Les plans de Taguchi ne sont qu'une technique particulière pour retrouver
des plans factoriels ou multifactoriels complets ou fractionnaires (à partir
d'une matrice, d'une table triangulaire et d'un graphe linéaire. Avec
les logiciels qui génèrent automatiquement les tables, cette
technique est devenue un peu désuette mais elle avait l'avantage à l'époque
de son utilisation de proposer une liste de plus d'une centaine de tables avec
des facteurs multiples à 2
ou plusieurs niveaux avec ou sans interactions. Voyons en quelques exemples
classiques pour la culture générale (car cela fait bien de les
connaître et en plus c'est joli).
Taguchi proposa d'organiser les expériences selon des tables et des graphes
qu'il appelle  où L signifie "Level" et
correspond aux nombres d'essais d'une expérience associés à des graphes permettant
d'identifier les interactions (les tables de Taguchi incluent certains plans
de Plackett-Burman). où L signifie "Level" et
correspond aux nombres d'essais d'une expérience associés à des graphes permettant
d'identifier les interactions (les tables de Taguchi incluent certains plans
de Plackett-Burman).
Commençons l'exemple avec une table que nous connaissons bien, la table  .
Chez Taguchi cette table peut être lue comme la table d'un plan factoriel fractionnaire
de 7 facteurs (donc sans interactions) où comme la table d'un plan factoriel
complet pour 3 facteurs. Raison pour laquelle est notée .
Chez Taguchi cette table peut être lue comme la table d'un plan factoriel fractionnaire
de 7 facteurs (donc sans interactions) où comme la table d'un plan factoriel
complet pour 3 facteurs. Raison pour laquelle est notée  tantôt tantôt  : :
Essais |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
3 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
4 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
5 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
6 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
7 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
8 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
Tableau: 74.26 - Table L8 avec notation factorielle d'usage et graphes linéaires correspondants
 
Nous allons voir si vraiment elle diffère de ce que nous connaissons déjà.
D'abord, chaque facteur ne prend aussi que deux niveaux dans ce tableau, nous
pouvons donc remplacer la notation de Taguchi avec notre notation d'usage pour
les plans factoriels en remplaçant les 1 par des "+" et les "2" par
des "-":
Essais |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
1 |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
2 |
+ |
+ |
+ |
- |
- |
- |
- |
3 |
+ |
- |
- |
+ |
+ |
- |
- |
4 |
+ |
- |
- |
- |
- |
+ |
+ |
5 |
- |
+ |
- |
+ |
- |
+ |
- |
6 |
- |
+ |
- |
- |
+ |
- |
+ |
7 |
- |
- |
+ |
+ |
- |
- |
+ |
8 |
- |
- |
+ |
- |
+ |
+ |
- |
Tableau: 74.27 - Table L8 avec notation factorielle d'usage
Nous voyons déjà beaucoup mieux que toutes les lignes et colonnes sont orthogonales
prises deux à deux (matrice d'Hadamard). Nous ajoutons une colonne de "+":
Essais |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Repos |
1 |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
2 |
+ |
+ |
+ |
- |
- |
- |
- |
+ |
3 |
+ |
- |
- |
+ |
+ |
- |
- |
+ |
4 |
+ |
- |
- |
- |
- |
+ |
+ |
+ |
5 |
- |
+ |
- |
+ |
- |
+ |
- |
+ |
6 |
- |
+ |
- |
- |
+ |
- |
+ |
+ |
7 |
- |
- |
+ |
+ |
- |
- |
+ |
+ |
8 |
- |
- |
+ |
- |
+ |
+ |
- |
+ |
Tableau: 74.28 - Table L8 avec notation factorielle d'usage avec colonne supplémentaire
manquante
et nous remarquons que nous retrouvons le plan factoriel complet de 3
facteurs à deux
niveaux si nous renotons la ligne de titre des colonnes de la manière suivante:
Essais |
F3 |
F2 |
F23 |
F1 |
F13 |
F12 |
F123 |
Repos |
1 |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
2 |
+ |
+ |
+ |
- |
- |
- |
- |
+ |
3 |
+ |
- |
- |
+ |
+ |
- |
- |
+ |
4 |
+ |
- |
- |
- |
- |
+ |
+ |
+ |
5 |
- |
+ |
- |
+ |
- |
+ |
- |
+ |
6 |
- |
+ |
- |
- |
+ |
- |
+ |
+ |
7 |
- |
- |
+ |
+ |
- |
- |
+ |
+ |
8 |
- |
- |
+ |
- |
+ |
+ |
- |
+ |
Tableau: 74.29 - Tableau précédent avec notation traditionelle pour la ligne de titre
et que cela correspond aussi au plan factoriel fractionnaire d'un plan d'expérience
de 7 facteurs à deux niveaux (sans aucune interaction).
La question que se posera bien évidemment le lecteur, c'est comment aurions
nous fait pour identifier quel facteur appartenait à quelle colonne dans le
cadre d'un plan factoriel complet à 3 facteurs si nous ne connaissions pas
le tableau établi avec les techniques vues plus haut? Eh bien en utilisant
le graphe linéaire suivant:
Figure: 74.43 - Graphe linéaire de Taguchi L8
qui indique les facteurs principaux dans les sommets du graphe (donc les colonnes
1, 2 et 4 sont des facteurs principaux). La colonne 3 est l'interaction entre
les colonnes 1 et 2 (d'où le fait qu'elle se trouve sur l'arête qui sépare
les deux sommets), la colonne 5 est l'interaction entre les colonnes 1 et 4
(d'où le fait qu'elle se trouve sur l'arête qui sépare les deux sommets), et
la colonne 6 est l'interaction entre les colonnes 2 et 4 (d'où le fait qu'elle
se trouve sur l'arête qui sépare les deux sommets). Le fait que le 7 soit à l'extérieur,
c'est parce qu'une triple interaction ne peut pas être représentée avec cette
technique de graphe planaire. On utilise alors les symboles des sommets pour
signifier que c'est la superposition du sommet 1, 2 et 4 (cercle+anneau+disque).
Le deuxième graphe linéaire associé à cette table permet de mettre en évidence
un autre usage possible:
Figure: 74.44 - Graphe linéaire de Taguchi L8
C'est-à-dire d'en faire usage pour une analyse de 4 facteurs (toujours à deux
modalités dans le cas présent) représentées par les colonnes 1, 2, 4, 7 (le
lecteur pourra effectivement vérifier que ces quatre colonnes correspondent
bien à un plan factoriel fractionnaire avec pour générateur 12 pour 4 facteurs
soit à la main, soit avec un logiciel) dont 3 interactions (1 et 2; 1 et 4;
1 et 7).
Remarque: Il faut faire attention car il y a donc par exemple une table de
Taguchi notée donc pour
3 facteurs à 2 niveaux complète et 7 facteurs à 2 niveaux sans interactions
comme nous venons de le voir (donc avec 7 colonnes), mais il y a aussi des
tables pour
5 facteurs décomposés en 4 facteurs à 3 niveaux et 1 facteur à 4 niveaux (sans
interactions) mais seulement avec 5 colonnes. Raison pour laquelle les livres
listant les tables de Taguchi spécifient normalement explicitement le cadre
d'application des tables.
Voyons quelques autres tables (une infime partie de la liste complète)
- Table 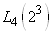 : :
Essais |
F1 |
F2 |
F3 |
1 |
1 |
1 |
1 |
2 |
1 |
2 |
2 |
3 |
2 |
1 |
2 |
4 |
2 |
2 |
1 |
Tableau: 74.30 - Table L4 de Taguchi

- Table 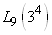 : :
Essais |
F1 |
F2 |
F3 |
F4 |
1 |
1 |
1 |
1 |
1 |
2 |
1 |
2 |
2 |
2 |
3 |
1 |
3 |
3 |
3 |
4 |
2 |
1 |
2 |
3 |
5 |
2 |
2 |
3 |
1 |
6 |
2 |
3 |
1 |
2 |
7 |
3 |
1 |
3 |
2 |
8 |
3 |
2 |
1 |
3 |
9 |
3 |
3 |
2 |
1 |
Tableau: 74.31 - Table L9 de Taguchi

- Table 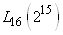 : :
Essais |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
F8 |
F9 |
F10 |
F11 |
F12 |
F13 |
F14 |
F15 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
3 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
4 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
1 |
1 |
1 |
1 |
5 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
6 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
7 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
8 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
1 |
1 |
2 |
2 |
9 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
10 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
1 |
11 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
12 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
1 |
1 |
2 |
1 |
2 |
13 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
14 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
2 |
15 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
16 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
2 |
1 |
1 |
2 |
1 |
2 |
2 |
1 |
Tableau: 74.32 - Table L16 de Taguchi

- Table 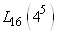 : :
Essais |
F1 |
F2 |
F3 |
F4 |
F5 |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
1 |
2 |
2 |
2 |
2 |
3 |
1 |
3 |
3 |
3 |
3 |
4 |
1 |
4 |
4 |
4 |
4 |
5 |
2 |
1 |
2 |
3 |
4 |
6 |
2 |
2 |
1 |
4 |
3 |
7 |
2 |
3 |
4 |
1 |
2 |
8 |
2 |
4 |
3 |
2 |
1 |
9 |
3 |
1 |
3 |
4 |
2 |
10 |
3 |
2 |
4 |
3 |
1 |
11 |
3 |
3 |
1 |
2 |
4 |
12 |
3 |
4 |
2 |
1 |
3 |
13 |
4 |
1 |
4 |
2 |
3 |
14 |
4 |
2 |
3 |
1 |
4 |
15 |
4 |
3 |
2 |
4 |
1 |
16 |
4 |
4 |
1 |
3 |
2 |
Tableau: 74.33 - Table L16 de Taguchi

etc.
Les tables de Taguchi accompagnées de leurs graphes sont donc des plans factoriels
fractionnaires ou complets avec tous leurs avantages. Le mérite de Taguchi
est d'avoir essayé de simplifier l'utilisation des plans factoriels pour les
rendre accessibles à un grand nombre d'expérimentateurs.
Enfin résumons ce que nous avons vu jusqu'à maintenant avec
les noms respectifs (à vérifier
car il n'y a priori pas de norme claire à notre
connaissance concernant ces définitions) dans l'ordre de généralisation:
- les plans qui contiennent uniquement des facteurs à deux niveaux,
sont désignés sous le nom de "plans
factoriels" qu'ils
soient avec un modèle linéaire ou non-linéaire, additif
ou non.
- les plans factoriels qui permettent uniquement de déterminer les
coefficients des facteurs principaux
(donc modèle
additif: sans interactions) sont désignés sous le nom de "plans
de Koshal" ou "plans
de criblage" (appelés aussi "plans un à la
fois" car comme la technique du "un à la fois" il ne permettent d'analyser
aucune interaction mais le comparaison s'arrête là!).
- les plans factoriels où toutes les interactions d'ordre trois et
supérieures
sont négligées sont désignés sous le nom de "plans
de Rechtschaffner".
- les plans factoriels où les coefficients ont été aliasés
tout en gardant les interactions sont désignés sous le nom
de "plans
factoriels fractionnaires", ou encore de "plans
de Box et Hunter"
ou encore sous le nom de "plans
basés sur
la matrice d'Hadamard". Avec les plans factoriels fractionnaires,
il convient de préciser aussi la résolution.
- les plans factoriels dont l'ordre est un multiple de quatre mais pas
une puissance de deux (donc 12, 16, 20, 24, etc.) sont sont désignés
sous lenom de "plans
de Plackett-Burman".
- les plans avec un nombre quelconque de facteurs, d'interactions d'ordre
quelconque et à un nombre de niveaux quelconque sont désignés
sous le nom de "plans
de Fisher" (en hommage au créateur d'origine du concept
de plan d'expérience).
- les plans qui contiennent autant d'essais que de coefficients à déterminer
sont désignés sous le nom de "plans saturés".
- les plans qui contiennent moins d'essais que de coefficients à déterminer
sont désignés sous le nom de "plans sursaturés".
Un aspect mérite encore d'être précisé: c'est
la vérification
de la validité du modèle mathématique du premier degré.
Or aucun de ces plans ne prévoit un tel test de validité utilisant
des statistiques élaborées. C'est pourquoi il est préconisé de
toujours ajouter au moins un point expérimental au centre du domaine
expérimental. La valeur de la réponse en ce point sera comparée à la
valeur déduite des autres points expérimentaux grâce
au modèle mathématique. Si les deux valeurs sont semblables,
le modèle mathématique sera adopté, si elles ne le
sont pas nous devrons rejeter ce modèle et compléter les
résultats
déjà obtenus par des expériences permettant de passer
au second degré.
Enfin, pour terminer, faisons un exemple particulier et relativement complet
d'un plan factoriel complet général avec des facteurs à 3
niveaux.
Exemple:
Dans le cadre de l'étude de pneus, le critère retenu sera la longévité (nombre
de kilomètres parcourus avant que le pneu soit usé) et les facteurs pourront être
l'usage (ville ou route), la vitesse moyenne (40 [km/h] ou 50
[km/h]) et la pression de gonflage (1.5 ou 2 ou 2.5 [kg]).
La deuxième étape est la création du plan d'expérience. Dans un plan factoriel
complet, nous croisons les différents niveaux de tous les facteurs de façon à tester
chaque combinaison. Par exemple pour les pneus, nous serons amenés à réaliser 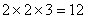 expériences
au minimum si nous voulons travailler avec un plan complet. Par ailleurs, il
est plus sain de répéter les expériences (pour analyser la dispersion des valeurs),
donc d'en faire 24, 36, etc. expériences
au minimum si nous voulons travailler avec un plan complet. Par ailleurs, il
est plus sain de répéter les expériences (pour analyser la dispersion des valeurs),
donc d'en faire 24, 36, etc.
Nous noterons comme à l'habitude y la variable étudiée et dans le cas
présent 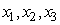 les
variables facteurs. Nous recherchons un modèle simple sous la forme: les
variables facteurs. Nous recherchons un modèle simple sous la forme:
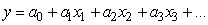 (74.342)
(74.342)
Comme chacun des facteurs peut avoir plusieurs niveau, nous aurons par exemple
la valeur y au niveau 2 du facteur 1 et au niveau 1 du facteur 2 et
au niveau 3 du facteur 3 qui sera noté:
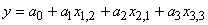 (74.343)
(74.343)
Le plan factoriel complet est l'exposé des types d'expériences suivant les
niveaux. Par exemple, pour l'étude des pneus nous aurons:
- Pour le facteur 1 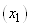 lieu:
ville = 1, route = 2 lieu:
ville = 1, route = 2
- Pour le facteur 2 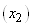 vitesse:
40 [km/h] = 1, 50 [km/h] = 2 vitesse:
40 [km/h] = 1, 50 [km/h] = 2
- Pour le facteur 3 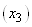 pression
de pneus: 1.5 [kg] =1, 2 [kg] = 2, 2.5 [kg] = 3 pression
de pneus: 1.5 [kg] =1, 2 [kg] = 2, 2.5 [kg] = 3
La matrice d'expérimentation sera alors (c'est exactement la même que celle
que l'on obtient en général avec Minitab un plan factoriel complet pour 3 facteurs
avec 2 à deux niveaux et 1 un trois niveaux sans randomisation):
Essai N° |

|

|

|
1 |
1 |
1 |
1 |
2 |
1 |
1 |
2 |
3 |
1 |
1 |
3 |
4 |
1 |
2 |
1 |
5 |
1 |
2 |
2 |
6 |
1 |
2 |
3 |
7 |
2 |
1 |
1 |
8 |
2 |
1 |
2 |
9 |
2 |
1 |
3 |
10 |
2 |
2 |
1 |
11 |
2 |
2 |
2 |
12 |
2 |
2 |
3 |
Tableau: 74.34 - Matrice d'expérimentation (ou tableau factoriel/plan d'expérience)
À ce tableau, nous pourrons associer les résultats des expériences. Par exemple,
pour les pneus, nous avons fait trois essais (trois "réplications")
pour chacune des conditions de niveaux et nous avons obtenu:
N° Essai |
|
|
|
Valeurs |
de |
y |
1 |
1 |
1 |
1 |
32'700 |
32'750 |
32'960 |
2 |
1 |
1 |
2 |
33'430 |
33'360 |
32'910 |
3 |
1 |
1 |
3 |
31'710 |
32'100 |
32'220 |
4 |
1 |
2 |
1 |
32'680 |
32'270 |
33'130 |
5 |
1 |
2 |
2 |
34'070 |
33'100 |
33'610 |
6 |
1 |
2 |
3 |
33'220 |
33'700 |
33'285 |
7 |
2 |
1 |
1 |
33'180 |
32'160 |
32'640 |
8 |
2 |
1 |
2 |
34'430 |
34'280 |
34'460 |
9 |
2 |
1 |
3 |
33'570 |
33'300 |
32'570 |
10 |
2 |
2 |
1 |
33'270 |
33'080 |
32'415 |
11 |
2 |
2 |
2 |
33'440 |
33'570 |
34'204 |
12 |
2 |
2 |
3 |
32'840 |
33'210 |
32'470 |
Tableau: 74.35 - Matrice d'expérimentation avec valeurs expérimentales
À l'aide de ces valeurs, nous pouvons calculer les effets des différents facteurs.
Nous partons du principe que leur moyenne est nulle pour un facteur donné.
Donc la valeur moyenne arithmétique globale (qui peut être calculée comme la
moyenne arithmétique si et seulement si les variables sont codées):
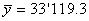 (74.344)
(74.344)
est le coefficient constant du modèle:
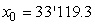 (74.345)
(74.345)
L'effet de au
niveau 1 est la variation de cette moyenne quand on ne considère que
les cas où est
au niveau 1. La moyenne arithmétique devient 32'955.8, donc l'effet est:
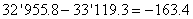 (74.346)
(74.346)
Nous noterons cela:
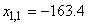 (74.347)
(74.347)
Au niveau 2 de ,
la moyenne devient 33'282.7 donc l'effet de au
niveau 2 vaut:
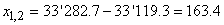 (74.348)
(74.348)
Nous remarquons que la somme des effets de est
nulle, car c'est la somme des écarts à la moyenne de sous-populations de même
taille (donc la moyenne globale est la moyenne arithmétique des moyennes des
niveaux).
Exactement de la même façon, nous trouvons:
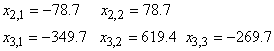 (74.349)
(74.349)
et nous retrouvons aussi que la somme des effets sur une variable est nulle.
Nous modélisons ces résultats sous la forme utilisant la moyenne de réponse
(remarquez que la somme de chaque vecteur est donc nulle):
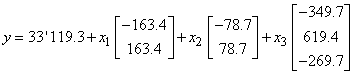 (74.350)
(74.350)
qui donne le modèle trouvé. Fonction que nous pouvons récrire sous la forme
d'effet moyen (la forme la plus intéressante mathématiqument parlant):
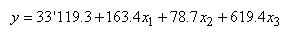 (74.351)
(74.351)
Résultat intermédiaire à comparer avec une régression linéaire simple qui
est (résultat parfaitement identique entre Microsoft Excel 14.0.6117
et Minitab 15.1.1):
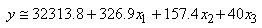 (74.352)
(74.352)
mais qui n'a pas de sens puisque la régression linéaire n'est pas construite
pour des facteurs à plus de deux niveaux.
De ces résultats, nous tirons déjà la meilleure stratégie d'utilisation des
pneus: sur route, à 50 [km/h], et avec un pneu gonflé à 2 [kg],
nous pouvons espérer faire:
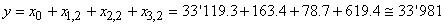 (74.353)
(74.353)
Remarquons tout de suite que dans certains cas, l'expérimentation a fait mieux,
même en ville ou à 40 [km/h]. Ceci relève de la dispersion évidente
des résultats. Mais alors, les effets trouvés ne viennent-t-ils pas seulement
de cette dispersion? D'autre part nous avons étudié les effets indépendamment
les uns des autres. Mais il se pourrait qu'ils se renforcent. Nous allons étudier
ces questions dans la suite.
Reprenons nos 36 expériences, en comparant les valeurs obtenues et les prévisions
du modèle:
|
|
|
Mesuré |
Modèle |
Écart |
|
|
|
|
Mesuré |
Modèle |
Écart |
1 |
1 |
1 |
32'700 |
32'527.5 |
172.5 |
|
2 |
1 |
1 |
32'160 |
32'854.3 |
-694.3 |
1 |
1 |
2 |
33'430 |
33'496.6 |
-66.6 |
|
2 |
1 |
2 |
34'280 |
33'823.4 |
456.6 |
1 |
1 |
3 |
31'710 |
32'607.5 |
-897.5 |
|
2 |
1 |
3 |
33'300 |
32'934.3 |
365.7 |
1 |
2 |
1 |
32'680 |
32'684.9 |
-4.9 |
|
2 |
2 |
1 |
33'080 |
33'011.7 |
68.3 |
1 |
2 |
2 |
34'070 |
33'654 |
416 |
|
2 |
2 |
2 |
33'570 |
33'980.8 |
-410.8 |
1 |
2 |
3 |
33'220 |
32'764.9 |
455.1 |
|
2 |
2 |
3 |
33'210 |
33'091.7 |
118.3 |
2 |
1 |
1 |
33'180 |
32'854.3 |
325.7 |
|
1 |
1 |
1 |
32'960 |
32'527.5 |
432.5 |
2 |
1 |
2 |
34'430 |
33'823.4 |
606.6 |
|
1 |
1 |
2 |
32'910 |
33'496.6 |
-586.6 |
2 |
1 |
3 |
33'570 |
32'934.3 |
635.7 |
|
1 |
1 |
3 |
32'220 |
32'607.5 |
-387.5 |
2 |
2 |
1 |
33'270 |
33'011.7 |
258.3 |
|
1 |
2 |
1 |
33'130 |
32'684.9 |
445.1 |
2 |
2 |
2 |
33'440 |
33'980.8 |
-540.8 |
|
1 |
2 |
2 |
33'610 |
33'654 |
-44 |
2 |
2 |
3 |
32'840 |
33'091.7 |
-251.7 |
|
1 |
2 |
3 |
33'285 |
32'764.9 |
520.1 |
1 |
1 |
1 |
32'750 |
32'527.5 |
222.5 |
|
2 |
1 |
1 |
32'640 |
32'854.3 |
-214.3 |
1 |
1 |
2 |
33'360 |
33'496.6 |
-136.6 |
|
2 |
1 |
2 |
34'460 |
33'823.4 |
636.6 |
1 |
1 |
3 |
32'100 |
32'607.5 |
-507.5 |
|
2 |
1 |
3 |
32'570 |
32'934.3 |
-364.3 |
1 |
2 |
1 |
32'270 |
32'684.9 |
-414.9 |
|
2 |
2 |
1 |
32'415 |
33'011.7 |
-596.7 |
1 |
2 |
2 |
33'100 |
33'654 |
-554 |
|
2 |
2 |
2 |
34'204 |
33'980.8 |
223.2 |
1 |
2 |
3 |
33'700 |
32'764.9 |
935.1 |
|
2 |
2 |
3 |
32'470 |
33'091.7 |
-621.7 |
Tableau: 74.36 - Matrice d'expérience comparant expérience et modèle
Nous constatons que les écarts au modèle sont parfois importants. Cela peut
venir d'une dispersion aléatoire naturelle des valeurs, ou bien d'un modèle
inadapté. Cela fait penser à un modèle inadapté, ou bien cela pourrait être
dû à ce que des facteurs conjugués ont plus d'effet que séparés. Les effets
positifs ou négatifs de 2 facteurs peuvent faire plus que s'additionner (modèle
purement additif à rejeter peut-être).
Il y a donc probablement des interactions (les chimistes parlent de "potentialisation").
Pour voir s'il y en a des interactions d'ordre deux, un bon moyen c'est d'étudier
tous les facteurs par paires (et faire abstraction de l'existence des autres).
Ainsi, si nous commençons avec les facteurs (lieu) et (vitesse) en
faisant abstraction de la pression des pneus, nous aurons (l'explication se
trouve après la première ligne):
Niveaux |
Moyenne expérimentale |
Effet total |
Somme des effets |
Effet de l'interaction |

|
32'682.2 |
-437.1 |
-242.2 |
-194.9 |

|
33'229.4 |
110.2 |
-84.7 |
194.9 |

|
33'398.9 |
279.6 |
84.7 |
194.9 |

|
33'166.6 |
47.3 |
242.2 |
-194.9 |
Tableau: 74.37 - Tableau d'interaction facteurs 1 et 2
Donc, 32'682.2 est la moyenne arithmétique des expériences faites au niveau  (Ville)
et (Ville)
et  (40 [km/h]).
En soustrayant la moyenne (toujours 33'119.3), Nous obtenons un effet de -437.1,
alors que l'effet de (-163.4)
plus l'effet de (-78.7)
ne donne que –242.2. (40 [km/h]).
En soustrayant la moyenne (toujours 33'119.3), Nous obtenons un effet de -437.1,
alors que l'effet de (-163.4)
plus l'effet de (-78.7)
ne donne que –242.2.
Il y a donc un surplus de –194.9, dû en grande partie à l'interaction (notez
que c'est la même pour ,
et l'opposée pour et ).
Notons tout de suite que l'interaction a
un effet bien supérieur aux effets de et
de !
Voyons les deux autres interactions possibles:
Niveaux |
Moyenne expérimentale |
Effet total |
Somme des effets |
Effet de l'interaction |
|
32'748.3 |
-370.9 |
-513.1 |
142.2 |

|
33'413.3 |
294.1 |
455.9 |
-161.9 |

|
32'705.8 |
-413.4 |
-433.1 |
19.7 |

|
32'790.8 |
-328.4 |
-186.3 |
-142.2 |

|
34'064.0 |
944.7 |
782.8 |
161.9 |

|
32'993.3 |
-125.9 |
-106.3 |
-19.7 |
Tableau: 74.38 - Tableau d'interaction facteurs 1 et 3
Niveaux |
Moyenne expérimentale |
Effet total |
Somme des effets |
Effet de l'interaction |

|
32'731.7 |
-387.6 |
-428.4 |
40.8 |

|
33'811.7 |
692.4 |
540.7 |
151.7 |

|
32'578.3 |
-540.9 |
-348.4 |
-192.5 |

|
32'807.5 |
-311.8 |
-271.0 |
-40.8 |

|
33'665.7 |
546.4 |
698.1 |
-151.7 |

|
33'120.8 |
1.6 |
-191.0 |
192.5 |
Tableau: 74.39 - Tableau d'interaction facteurs 2 et 3
Nous pouvons représenter les interactions différemment, en croisant les facteurs:
|

|

|
|
-194.9 |
194.9 |

|
194.9 |
-194.9 |
|

|

|

|
|
142.2 |
-161.9 |
19.7 |
|
-142.2 |
161.9 |
-19.7 |
|
|
|
|
|
40.8 |
151.7 |
-192.5 |
|
-40.8 |
-151.7 |
192.5 |
Nous remarquons alors que chaque ligne ou chaque colonne a un total nul. Nous
voyons aussi que, dans ce cas, il est difficile de négliger les interactions,
et que  (par
exemple) intervient plus par ses interactions que par son effet propre! (par
exemple) intervient plus par ses interactions que par son effet propre!
Nous pouvons encore essayer de vérifier si l'interaction des trois facteurs
a un effet notable. L'expérience ayant été répétée 3 fois à chaque niveau
(nous parlons alors de "trois blocs"), nous pouvons calculer
la moyenne de y, et lui soustraire le modèle avec les interactions
calculé ci-dessus (remarquez que la somme de chaque vecteur est nulle):
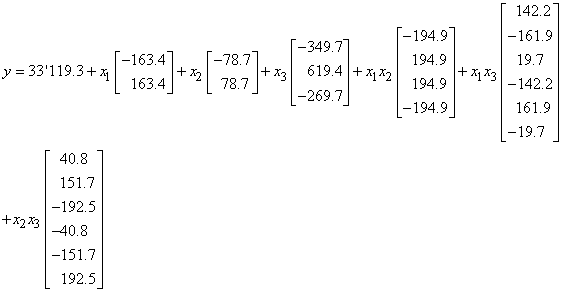 (74.354)
(74.354)
qu'il est d'usage d'écrire par souci de simplification évidente (remarquez
que la somme de chaque vecteur est nulle):
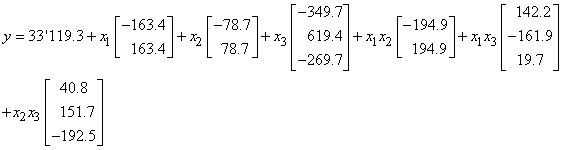 (74.355)
(74.355)
Remarque: Il suffit de savoir que pour les coefficients
d'interaction les effets manquants (non signalés) sont opposés en signe.
Certains logiciels de statistiques vont plus loin dans la simplification d'écriture
(toujours dans la même idée que les autres coefficients sont opposés) et écrivent:
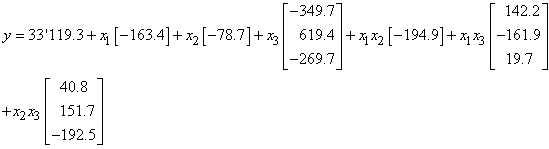 (74.356)
(74.356)
et d'autres logiciels (comme Minitab 15.1.1 par exemple) vont encore plus loin en écrivant:
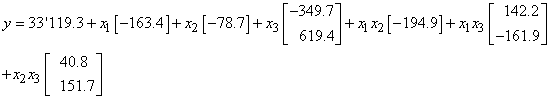 (74.357)
(74.357)
car les valeurs manquantes s'obtiennent par addition et en inversant le
signe (encore faut-il le savoir... à partir du fait que la somme de chaque
vecteur doit être nulle). Nous ne pouvons donc pas à cause
de la présence
du facteur à 3 niveaux réduire rigoureusement le modèle
mathématique à une
simple fonction. Raison pour laquelle, nous nous retrouvons avec la symbolique
visible dans la relation précédente.
Nous pouvons alors résumer ces résultats sous la forme:
N° Essai |
|
|
|
Valeurs |
de |
y |
Moyenne |
Modèle |
Écart |
1 |
1 |
1 |
1 |
32'700 |
32'750 |
32'960 |
32'803.3 |
32'515.6 |
287.8 |
2 |
1 |
1 |
2 |
33'430 |
33'360 |
32'910 |
33'233.3 |
33'291.5 |
-58.1 |
3 |
1 |
1 |
3 |
31'710 |
32'100 |
32'220 |
32'010.0 |
32'239.8 |
-229.8 |
4 |
1 |
2 |
1 |
32'680 |
32'270 |
33'130 |
32'693.3 |
32'981.2 |
-287.8 |
5 |
1 |
2 |
2 |
34'070 |
33'100 |
33'610 |
33'593.3 |
33'535.3 |
58.1 |
6 |
1 |
2 |
3 |
33'220 |
33'700 |
33'285 |
33'401.7 |
33'172.0 |
229.7 |
7 |
2 |
1 |
1 |
33'180 |
32'160 |
32'640 |
32'660.0 |
32'947.8 |
-287.8 |
8 |
2 |
1 |
2 |
34'430 |
34'280 |
34'460 |
34'390.0 |
34'331.9 |
58.1 |
9 |
2 |
1 |
3 |
33'570 |
33'300 |
32'570 |
33'146.7 |
32'917.0 |
229.7 |
10 |
2 |
2 |
1 |
33'270 |
33'080 |
32'415 |
32'921.7 |
32'633.8 |
287.9 |
11 |
2 |
2 |
2 |
33'440 |
33'570 |
34'204 |
33'738.0 |
33'796.1 |
-58.1 |
12 |
2 |
2 |
3 |
32'840 |
33'210 |
32'470 |
32'840.0 |
33'069.6 |
-229.6 |
Tableau: 74.40 - Matrice d'expérience avec mesures, moyenne, modèle et écart
Nous nous apercevons alors que les valeurs du modèle s'écartent toujours assez
nettement des valeurs moyennes, ce qui peut s'interpréter soit par le fait
que les effets ne sont pas linéaires, soit par une interaction entre les trois
facteurs.
Il conviendrait alors de refaire les calculs effectués plus haut avec l'interaction
des trois facteurs. Mais comme c'est toujours le même principe, nous le ferons
que si un lecteur ne nous le demande explicitement.
Mais il existe encore une cause d'erreur dans le modèle, c'est de tenir compte
d'effets qui n'interviennent pas en réalité. Pour être sûr que l'effet calculé sur
une variable ou sur une interaction est réel, nous utiliserons pour commencer
l'analyse de la variance à une voie (ANOVA) que nous avons étudié en détails
dans le chapitre de Statistiques. Pour cela, il est important d'avoir répété les
expériences, de façon à pouvoir mettre en évidence la dispersion due aux facteurs
non contrôlés.
Par exemple, le facteur a
un effet plutôt faible. A-t-il une influence véritable? Pour cela, nous
séparons
les 36 expériences en deux échantillons (niveau et
niveau  ),
et nous calculons les sommes de carrés et les degrés de liberté (nous pouvons
détailler les calculs ci-dessous sur demande): ),
et nous calculons les sommes de carrés et les degrés de liberté (nous pouvons
détailler les calculs ci-dessous sur demande):
sommes de carrés |
ddl |
variances |
F |
contrôlée |
223'098.78 |
1 |
223'099 |
calculé: |
0.485 |
résiduelle |
15'645'288.44 |
34 |
460'156 |
limite (5%): |
4.13 |
totale |
15'868'387.22 |
35 |
|
test réussi |
Tableau: 74.41 - Tableau d'ANOVA
Ce qui donne avec Minitab 15.1.1 (nous pouvons y constater que le modèle n'est très
probablement pas linéaire):

Le test ayant réussi, nous concluons que le facteur n'est
sans doute pas influent (car le test avait comme hypothèse: le facteur
contrôlé n'est
pas influent). Il en est de même pour le facteur 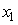 (nous
pouvons détailler les calculs ci-dessous sur demande): (nous
pouvons détailler les calculs ci-dessous sur demande):
sommes
de carrés |
ddl |
variances |
F |
contrôlée |
961'707.1 |
1 |
961'707 |
calculé: |
2.19 |
résiduelle |
14'906'680.1 |
34 |
438'432 |
limite (5%): |
4.13 |
totale |
15'868'387.2 |
35 |
|
test réussi |
Tableau: 74.42 - Tableau d'ANOVA
Ce qui donne avec Minitab 15.1.1 (nous pouvons aussi y constater que le modèle n'est
très probablement pas linéaire):

Par contre, le facteur est,
lui, bel et bien influent (nous pouvons détailler les calculs ci-dessous
sur demande):
sommes
de carrés |
ddl |
variances |
F |
contrôlée |
6'943'966,7 |
2 |
3'471'983 |
calculé: |
12.84 |
résiduelle |
8'924'420,5 |
33 |
270'437 |
limite (5%): |
3.28 |
totale |
15'868'387.2 |
35 |
|
test échoué |
Tableau: 74.43 - Tableau d'ANOVA
Ce qui donne avec Minitab 15.1.1 (nous pouvons y constater que le modèle n'est très
probablement pas linéaire):

Rappelons en effet que l'échec du test correspond à la mise en évidence d'un
facteur influent, celui qui est contrôlé. Alors, le modèle de base à considérer
(on laisse de côté les interactions) n'est plus :
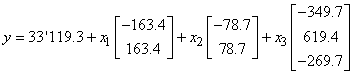 (74.358)
(74.358)
mais (la somme du vecteur étant toujours nulle):
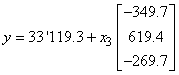 .
(74.359) .
(74.359)
Attention!!! Le fait que et ne
soient pas influents n'a pas comme conséquence que les interactions entre et ,
ou et ,
ou même 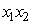 et ne
le sont pas. Par exemple, ici, n'est
pas influent (le test de Fischer-Snedecor réussit), mais au niveau 1 de , l'est
(au sens et ne
le sont pas. Par exemple, ici, n'est
pas influent (le test de Fischer-Snedecor réussit), mais au niveau 1 de , l'est
(au sens 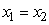 contre contre 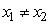 ). ).
Voyons cela avec Minitab 15.1.1 (nos pouvons détailler les calculs
ci-dessous sur demande):

Nous voyons qu'en faisant une ANOVA multifactorielle, que finalement le
facteur est
statistiquement significatif (p-value inférieure à 5%),
la vitesse par contre ne l'est pas (p-value supérieure à 5%), la
pression a une influence très significative (p-value nulle).
L'interaction (Lieu*Vitesse)
est significative (p-value inférieure à 5%). Par contre, les interactions 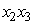 (Vitesse*Pression)
et (Vitesse*Pression)
et 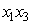 (Lieu*Pression)
ne sont pas significatives (p-value supérieure à 5%). La triple
interaction (Lieu*Vitesse*Pression) est elle significative! (Lieu*Pression)
ne sont pas significatives (p-value supérieure à 5%). La triple
interaction (Lieu*Vitesse*Pression) est elle significative!
Pour clore, rappelons que nous avons parlé plus haut de l'intérêt de randomiser
l'ordre des mesures pour éliminer les facteurs parasites inconnus. En réalité,
il faut considérer 3 cas importants de facteurs nuisibles dans la pratique
et qui ne font que de changer un tout petit peu l'ANOVA utilisée et que
la majorité des logiciels modernes proposent de nos jours:
1. Nous avons des "facteurs nuisibles inconnus et incontrôlables". Dès
lors nous faisons une ANOVA habituelle avec simplement l'ordre des mesures
qui sont randomisés.
2. Nous avons des "facteurs nuisibles connus et non contrôlables". Nous
parlons alors de "covariables" ou "cofacteurs" et utilisons une ANCOVA
(cf.
chapitre de Statistiques)
au lieu d'une simple ANOVA
3. Nous avons des "facteurs nuisibles connus et contrôllables" que nous
voulons éliminer de l'analyse de l'ANOVA. L'idée est alors d'utiliser une
technique dite de "Blocking" qui est simplement une ANOVA hiérarchisée
(cf. chapitre de Statistiques).
|
 6
6  0
0